Logistic Regression with a Neural Network mindset
吴恩达老师深度学习课程第一课“神经网络与深度学习”第二周神经网络基础课后编程。
https://github.com/zhengjie9510/deep-learning-coursera
Instructions:
- Do not use loops (for/while) in your code, unless the instructions explicitly ask you to do so.
You will learn to:
- Build the general architecture of a learning algorithm, including:
- Initializing parameters
- Calculating the cost function and its gradient
- Using an optimization algorithm (gradient descent)
- Gather all three functions above into a main model function, in the right order.
1 - Packages
First, let’s run the cell below to import all the packages that you will need during this assignment.
- numpy is the fundamental package for scientific computing with Python.
- h5py is a common package to interact with a dataset that is stored on an H5 file.
- matplotlib is a famous library to plot graphs in Python.
- PIL and scipy are used here to test your model with your own picture at the end.
1 | import numpy as np |
2 - Overview of the Problem set
Problem Statement: You are given a dataset (“data.h5”) containing:
- a training set of m_train images labeled as cat (y=1) or non-cat (y=0)
- a test set of m_test images labeled as cat or non-cat
- each image is of shape (num_px, num_px, 3) where 3 is for the 3 channels (RGB). Thus, each image is square (height = num_px) and (width = num_px).
You will build a simple image-recognition algorithm that can correctly classify pictures as cat or non-cat.
Let’s get more familiar with the dataset. Load the data by running the following code.
1 | # Loading the data (cat/non-cat) |
We added “_orig” at the end of image datasets (train and test) because we are going to preprocess them. After preprocessing, we will end up with train_set_x and test_set_x (the labels train_set_y and test_set_y don’t need any preprocessing).
Each line of your train_set_x_orig and test_set_x_orig is an array representing an image. You can visualize an example by running the following code. Feel free also to change the index value and re-run to see other images.
1 | # Example of a picture |
y = [1], it's a 'cat' picture.
Many software bugs in deep learning come from having matrix/vector dimensions that don’t fit. If you can keep your matrix/vector dimensions straight you will go a long way toward eliminating many bugs.
Exercise: Find the values for:
- m_train (number of training examples)
- m_test (number of test examples)
- num_px (= height = width of a training image)
Remember that train_set_x_orig is a numpy-array of shape (m_train, num_px, num_px, 3). For instance, you can access m_train by writing train_set_x_orig.shape[0].
1 | ### START CODE HERE ### (≈ 3 lines of code) |
Number of training examples: m_train = 209
Number of testing examples: m_test = 50
Height/Width of each image: num_px = 64
Each image is of size: (64, 64, 3)
train_set_x shape: (209, 64, 64, 3)
train_set_y shape: (1, 209)
test_set_x shape: (50, 64, 64, 3)
test_set_y shape: (1, 50)Expected Output for m_train, m_test and num_px:
| **m_train** | 209 |
| **m_test** | 50 |
| **num_px** | 64 |
For convenience, you should now reshape images of shape (num_px, num_px, 3) in a numpy-array of shape (num_px $$ num_px $$ 3, 1). After this, our training (and test) dataset is a numpy-array where each column represents a flattened image. There should be m_train (respectively m_test) columns.
Exercise: Reshape the training and test data sets so that images of size (num_px, num_px, 3) are flattened into single vectors of shape (num_px $$ num_px $$ 3, 1).
A trick when you want to flatten a matrix X of shape (a,b,c,d) to a matrix X_flatten of shape (b$$c$$d, a) is to use:
1 | X_flatten = X.reshape(X.shape[0], -1).T # X.T is the transpose of X |
1 | # Reshape the training and test examples |
train_set_x_flatten shape: (12288, 209)
train_set_y shape: (1, 209)
test_set_x_flatten shape: (12288, 50)
test_set_y shape: (1, 50)
sanity check after reshaping: [17 31 56 22 33]Expected Output:
| **train_set_x_flatten shape** | (12288, 209) |
| **train_set_y shape** | (1, 209) |
| **test_set_x_flatten shape** | (12288, 50) |
| **test_set_y shape** | (1, 50) |
| **sanity check after reshaping** | [17 31 56 22 33] |
To represent color images, the red, green and blue channels (RGB) must be specified for each pixel, and so the pixel value is actually a vector of three numbers ranging from 0 to 255.
One common preprocessing step in machine learning is to center and standardize your dataset, meaning that you substract the mean of the whole numpy array from each example, and then divide each example by the standard deviation of the whole numpy array. But for picture datasets, it is simpler and more convenient and works almost as well to just divide every row of the dataset by 255 (the maximum value of a pixel channel).
Let’s standardize our dataset.
1 | train_set_x = train_set_x_flatten / 255. |
What you need to remember:
Common steps for pre-processing a new dataset are:
- Figure out the dimensions and shapes of the problem (m_train, m_test, num_px, …)
- Reshape the datasets such that each example is now a vector of size (num_px * num_px * 3, 1)
- “Standardize” the data
3 - General Architecture of the learning algorithm
It’s time to design a simple algorithm to distinguish cat images from non-cat images.
You will build a Logistic Regression, using a Neural Network mindset. The following Figure explains why Logistic Regression is actually a very simple Neural Network!
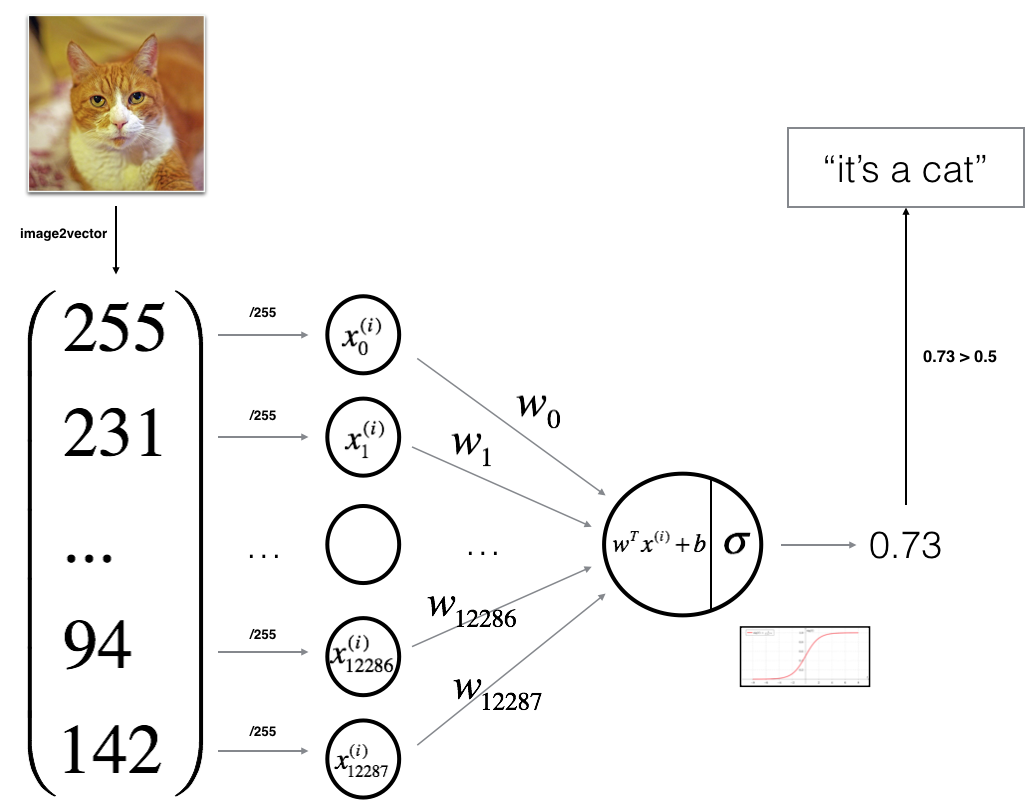
Mathematical expression of the algorithm:
For one example $x^{(i)}$:
$$z^{(i)} = w^T x^{(i)} + b \tag{1}$$
$$\hat{y}^{(i)} = a^{(i)} = sigmoid(z^{(i)})\tag{2}$$
$$ \mathcal{L}(a^{(i)}, y^{(i)}) = - y^{(i)} \log(a^{(i)}) - (1-y^{(i)} ) \log(1-a^{(i)})\tag{3}$$
The cost is then computed by summing over all training examples:
$$ J = \frac{1}{m} \sum_{i=1}^m \mathcal{L}(a^{(i)}, y^{(i)})\tag{6}$$
Key steps:
In this exercise, you will carry out the following steps:
- Initialize the parameters of the model
- Learn the parameters for the model by minimizing the cost
- Use the learned parameters to make predictions (on the test set)
- Analyse the results and conclude
4 - Building the parts of our algorithm
The main steps for building a Neural Network are:
- Define the model structure (such as number of input features)
- Initialize the model’s parameters
- Loop:
- Calculate current loss (forward propagation)
- Calculate current gradient (backward propagation)
- Update parameters (gradient descent)
You often build 1-3 separately and integrate them into one function we call model().
4.1 - Helper functions
Exercise: Using your code from “Python Basics”, implement sigmoid(). As you’ve seen in the figure above, you need to compute $sigmoid( w^T x + b)$ to make predictions.
1 | # GRADED FUNCTION: sigmoid |
1 | print ("sigmoid(0) = " + str(sigmoid(0))) |
sigmoid(0) = 0.5
sigmoid(9.2) = 0.999898970806Expected Output:
| **sigmoid(0)** | 0.5 |
| **sigmoid(9.2)** | 0.999898970806 |
4.2 - Initializing parameters
Exercise: Implement parameter initialization in the cell below. You have to initialize w as a vector of zeros. If you don’t know what numpy function to use, look up np.zeros() in the Numpy library’s documentation.
1 | # GRADED FUNCTION: initialize_with_zeros |
1 | dim = 2 |
w = [[ 0.]
[ 0.]]
b = 0Expected Output:
| ** w ** | [[ 0.] [ 0.]] |
| ** b ** | 0 |
For image inputs, w will be of shape (num_px $\times$ num_px $\times$ 3, 1).
4.3 - Forward and Backward propagation
Now that your parameters are initialized, you can do the “forward” and “backward” propagation steps for learning the parameters.
Exercise: Implement a function propagate() that computes the cost function and its gradient.
Hints:
Forward Propagation:
- You get X
- You compute $A = \sigma(w^T X + b) = (a^{(0)}, a^{(1)}, …, a^{(m-1)}, a^{(m)})$
- You calculate the cost function: $J = -\frac{1}{m}\sum_{i=1}^{m}y^{(i)}\log(a^{(i)})+(1-y^{(i)})\log(1-a^{(i)})$
Here are the two formulas you will be using:
$$ \frac{\partial J}{\partial w} = \frac{1}{m}X(A-Y)^T\tag{7}$$
$$ \frac{\partial J}{\partial b} = \frac{1}{m} \sum_{i=1}^m (a^{(i)}-y^{(i)})\tag{8}$$
1 | # GRADED FUNCTION: propagate |
1 | w, b, X, Y = np.array([[1], [2]]), 2, np.array([[1,2], [3,4]]), np.array([[1, 0]]) |
dw = [[ 0.99993216]
[ 1.99980262]]
db = 0.499935230625
cost = 6.00006477319Expected Output:
| ** dw ** | [[ 0.99993216] [ 1.99980262]] |
| ** db ** | 0.499935230625 |
| ** cost ** | 6.000064773192205 |
4.4 - Optimization
- You have initialized your parameters.
- You are also able to compute a cost function and its gradient.
- Now, you want to update the parameters using gradient descent.
Exercise: Write down the optimization function. The goal is to learn $w$ and $b$ by minimizing the cost function $J$. For a parameter $\theta$, the update rule is $ \theta = \theta - \alpha \text{ } d\theta$, where $\alpha$ is the learning rate.
1 | # GRADED FUNCTION: optimize |
1 | params, grads, costs = optimize(w, b, X, Y, num_iterations= 100, learning_rate = 0.009, print_cost = False) |
w = [[ 0.1124579 ]
[ 0.23106775]]
b = 1.55930492484
dw = [[ 0.90158428]
[ 1.76250842]]
db = 0.430462071679Expected Output:
| **w** | [[ 0.1124579 ] [ 0.23106775]] |
| db | 0.430462071679 |
Exercise: The previous function will output the learned w and b. We are able to use w and b to predict the labels for a dataset X. Implement the predict() function. There is two steps to computing predictions:
Calculate $\hat{Y} = A = \sigma(w^T X + b)$
Convert the entries of a into 0 (if activation <= 0.5) or 1 (if activation > 0.5), stores the predictions in a vector
Y_prediction. If you wish, you can use anif/elsestatement in aforloop (though there is also a way to vectorize this).
1 | # GRADED FUNCTION: predict |
1 | print("predictions = " + str(predict(w, b, X))) |
predictions = [[ 1. 1.]]Expected Output:
| **predictions** | [[ 1. 1.]] |
What to remember:
You’ve implemented several functions that:
- Initialize (w,b)
- Optimize the loss iteratively to learn parameters (w,b):
- computing the cost and its gradient
- updating the parameters using gradient descent
- Use the learned (w,b) to predict the labels for a given set of examples
5 - Merge all functions into a model
You will now see how the overall model is structured by putting together all the building blocks (functions implemented in the previous parts) together, in the right order.
Exercise: Implement the model function. Use the following notation:
- Y_prediction for your predictions on the test set
- Y_prediction_train for your predictions on the train set
- w, costs, grads for the outputs of optimize()
1 | # GRADED FUNCTION: model |
Run the following cell to train your model.
1 | d = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations = 2000, learning_rate = 0.005, print_cost = True) |
Cost after iteration 0: 0.693147
Cost after iteration 100: 0.584508
Cost after iteration 200: 0.466949
Cost after iteration 300: 0.376007
Cost after iteration 400: 0.331463
Cost after iteration 500: 0.303273
Cost after iteration 600: 0.279880
Cost after iteration 700: 0.260042
Cost after iteration 800: 0.242941
Cost after iteration 900: 0.228004
Cost after iteration 1000: 0.214820
Cost after iteration 1100: 0.203078
Cost after iteration 1200: 0.192544
Cost after iteration 1300: 0.183033
Cost after iteration 1400: 0.174399
Cost after iteration 1500: 0.166521
Cost after iteration 1600: 0.159305
Cost after iteration 1700: 0.152667
Cost after iteration 1800: 0.146542
Cost after iteration 1900: 0.140872
train accuracy: 99.04306220095694 %
test accuracy: 70.0 %Expected Output:
Comment: Training accuracy is close to 100%. This is a good sanity check: your model is working and has high enough capacity to fit the training data. Test error is 68%. It is actually not bad for this simple model, given the small dataset we used and that logistic regression is a linear classifier. But no worries, you’ll build an even better classifier next week!
Also, you see that the model is clearly overfitting the training data. Later in this specialization you will learn how to reduce overfitting, for example by using regularization. Using the code below (and changing the index variable) you can look at predictions on pictures of the test set.
1 | # Example of a picture that was wrongly classified. |
y = 0, you predicted that it is a "cat" picture.
/opt/conda/lib/python3.5/site-packages/ipykernel/__main__.py:4: DeprecationWarning: using a non-integer number instead of an integer will result in an error in the future
Let’s also plot the cost function and the gradients.
1 | # Plot learning curve (with costs) |
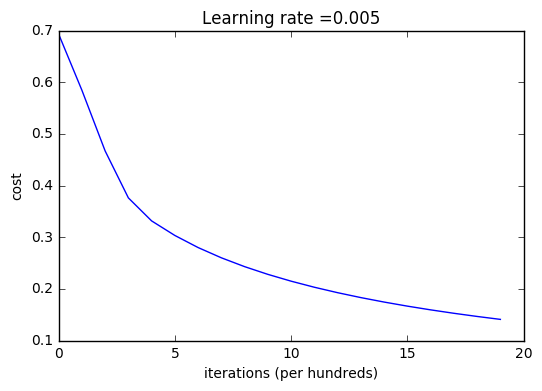
Interpretation:
You can see the cost decreasing. It shows that the parameters are being learned. However, you see that you could train the model even more on the training set. Try to increase the number of iterations in the cell above and rerun the cells. You might see that the training set accuracy goes up, but the test set accuracy goes down. This is called overfitting.
6 - Further analysis (optional/ungraded exercise)
Congratulations on building your first image classification model. Let’s analyze it further, and examine possible choices for the learning rate $\alpha$.
Choice of learning rate
Reminder:
In order for Gradient Descent to work you must choose the learning rate wisely. The learning rate $\alpha$ determines how rapidly we update the parameters. If the learning rate is too large we may “overshoot” the optimal value. Similarly, if it is too small we will need too many iterations to converge to the best values. That’s why it is crucial to use a well-tuned learning rate.
Let’s compare the learning curve of our model with several choices of learning rates. Run the cell below. This should take about 1 minute. Feel free also to try different values than the three we have initialized the learning_rates variable to contain, and see what happens.
1 | learning_rates = [0.01, 0.001, 0.0001] |
learning rate is: 0.01
train accuracy: 99.52153110047847 %
test accuracy: 68.0 %
-------------------------------------------------------
learning rate is: 0.001
train accuracy: 88.99521531100478 %
test accuracy: 64.0 %
-------------------------------------------------------
learning rate is: 0.0001
train accuracy: 68.42105263157895 %
test accuracy: 36.0 %
-------------------------------------------------------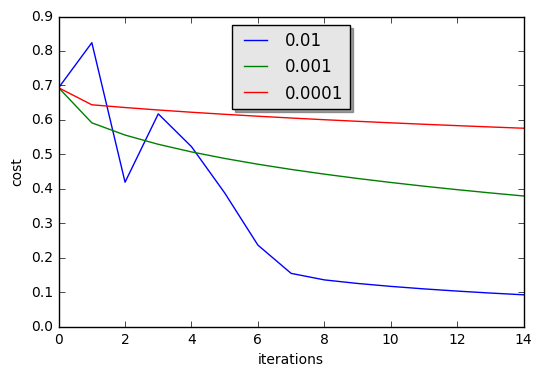
Interpretation:
- Different learning rates give different costs and thus different predictions results.
- If the learning rate is too large (0.01), the cost may oscillate up and down. It may even diverge (though in this example, using 0.01 still eventually ends up at a good value for the cost).
- A lower cost doesn’t mean a better model. You have to check if there is possibly overfitting. It happens when the training accuracy is a lot higher than the test accuracy.
- In deep learning, we usually recommend that you:
- Choose the learning rate that better minimizes the cost function.
- If your model overfits, use other techniques to reduce overfitting. (We’ll talk about this in later videos.)
7 - Test with your own image (optional/ungraded exercise)
Congratulations on finishing this assignment. You can use your own image and see the output of your model. To do that:
1. Click on “File” in the upper bar of this notebook, then click “Open” to go on your Coursera Hub.
2. Add your image to this Jupyter Notebook’s directory, in the “images” folder
3. Change your image’s name in the following code
4. Run the code and check if the algorithm is right (1 = cat, 0 = non-cat)!
1 | ## START CODE HERE ## (PUT YOUR IMAGE NAME) |
y = 0.0, your algorithm predicts a "non-cat" picture.
What to remember from this assignment:
- Preprocessing the dataset is important.
- You implemented each function separately: initialize(), propagate(), optimize(). Then you built a model().
- Tuning the learning rate (which is an example of a “hyperparameter”) can make a big difference to the algorithm. You will see more examples of this later in this course!
Finally, if you’d like, we invite you to try different things on this Notebook. Make sure you submit before trying anything. Once you submit, things you can play with include:
- Play with the learning rate and the number of iterations
- Try different initialization methods and compare the results
- Test other preprocessings (center the data, or divide each row by its standard deviation)
Bibliography: