🔍 为什么你用 AI 做的 PPT 不好看?因为你缺了这份技能
同样是 AI,为什么 Claude 做的 PPT 更让你满意?答案藏在它的'内部文件'里。Claude 处理 PPT 任务时,会先读一份专项操作手册——里面不只有流程,还内嵌了完整的设计规范:10套预设配色方案、字号排版规则,以及一份专门列出'AI做PPT最容易犯的毛病'的禁止清单。

前几天我用 Claude 做了一个演示文稿。沟通好需求之后,它直接写了一段代码,没多久就输出了一份排版挺不错的 PPT。
但让我真正好奇的,是它怎么知道不要在标题下面加装饰横线、不要用米黄色背景、不要做纯文字幻灯片——这些细节,它根本没问过我,就直接做对了。
与其猜,不如直接翻开内部文件看个究竟。毕竟知其然,还要知其所以然,才能真正用好这些工具。今天就把这份解读分享给大家。
📚 什么是技能?
技能(Skill)就是给 LLM 配备的一本”专项操作手册” ——里面写好了遇到特定任务时该怎么思考、用什么工具、遵守哪些规矩。
如果你对技能的概念还不太熟悉,可以先看看我之前写的《别再复制粘贴提示词了!AI Agent Skill 到底是什么?》。
PPTX 技能就是专门处理 PPT 的那本手册。 只要你跟 Claude 提到演示文稿、幻灯片之类的需求,它就会先翻开这本手册,按上面的流程来做事。
🗂️ 技能的整体目录结构
打开这个技能的文件夹,结构是这样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
pptx/
├── SKILL.md ← 主入口,Claude 第一个读的文件
├── editing.md ← 基于已有模板修改 PPT 的工作流
├── pptxgenjs.md ← 从零创建 PPT 的操作手册
└── scripts/
├── thumbnail.py ← 把 PPT 生成缩略图,用于快速预览
├── add_slide.py ← 复制或新建幻灯片
├── clean.py ← 清理临时文件
└── office/
├── unpack.py ← 把 .pptx 文件"拆开"
├── pack.py ← 修改后重新"打包"成 .pptx
├── soffice.py ← 把 PPT 渲染成图片
└── validate.py ← 打包前检查文件合法性
核心逻辑很清晰:
主入口 SKILL.md → 两种工作流(editing / pptxgenjs)→ 一套幕后工具(scripts)
⚙️ SKILL.md:Claude 的”第一眼”
每次 Claude 要处理 PPT 需求,它读的第一个文件就是 SKILL.md。这个文件起”总控”作用,里面有三块关键内容。
第一块:路由判断
手册里有一张简单的对照表,告诉 Claude 根据情况走哪条路:
- 用户给了模板 → 去读
editing.md,按模板修改 - 从零开始 → 去读
pptxgenjs.md,用代码生成
第二块:设计规范(最值得看的部分)
配色方面, 手册里列了 10 套提前搭配好的主题色盘,每套都包含主色、辅色和强调色。Claude 不用自己随便选颜色,而是从经过设计的方案里挑一套最符合主题的。
排版方面, 手册规定了标题字号、正文字号、推荐字体组合、段落间距,相当具体。
更有意思的是手册里的禁止清单——专门列出 AI 做 PPT 最容易犯的毛病,要求 Claude 主动避开:
- ❌ 不许每张幻灯片都用同一个布局(容易千篇一律、无聊)
- ❌ 不许在标题下面加装饰横线(这是 AI 生成 PPT 的典型特征,一眼就看得出来)
- ❌ 不许用米黄色背景(没有设计感)
- ❌ 不许做纯文字幻灯片(每张都必须有图、图表或图标)
- ❌ 不许把正文居中对齐(居中只适合标题,正文要靠左)
看到这里,开头那个问题就有了答案——Claude 之所以知道这些细节,是因为有人提前把每一条踩过的坑都写了进去。
第三块:质检流程
手册规定,初版做完之后必须过一遍视觉检查——把每张幻灯片渲染成图片,逐一排查溢出、遮挡、对齐等问题。这个环节是强制的,不是可选项。
🛠️ pptxgenjs.md:从零造 PPT 的核心手册
当没有模板时,Claude 使用一个叫 PptxGenJS 的工具,通过写代码的方式来画PPT。
把这个过程想象成用乐高积木搭东西 ——每一段代码对应一个积木块:这块是文字框、那块是图表、另一块是背景色。精确指定每个元素的位置、尺寸、颜色,所有积木按坐标拼好之后,一键生成 .pptx 文件。
踩坑记录:比正常用法更值钱的部分
手册里有一节叫”常见陷阱”,专门列出容易踩的坑,每条都有正确和错误的对比:
- 颜色值如果多加了一个
#符号,整个文件就会损坏 - 某个配置如果重复使用而不是每次重新创建,第二次调用时数据就会出错
这些问题光靠猜是猜不到的,必须有人提前踩过、记录下来,Claude 才能一次做对。
图表处理原则
手册明确规定:
只要 PPT 原生支持的图表类型(条形图、折线图、饼图等),就必须用原生图表,不允许截图代替。
原因很实在:用户拿到文件之后还能继续修改数据,截图就彻底”死”了。
📝 editing.md:基于模板修改 PPT 的流水线
当用户提供了现成的 PPT 模板,工作方式就不一样了。
核心思路: .pptx 文件本质上是一个压缩包,里面装的是一堆描述”这张幻灯片长什么样”的文本文件。Claude 会把这个压缩包解开,直接修改里面的内容,再重新压缩回去。
完整流程(七步)
1
2
3
4
5
6
7
1️⃣ 生成模板缩略图,看清楚每个版式长什么样
2️⃣ 规划内容与版式的对应关系
3️⃣ 把 .pptx 解包,得到可以直接编辑的文件
4️⃣ 完成所有结构性操作(删幻灯片、复制、调顺序)
5️⃣ 逐张修改每张幻灯片的内容
6️⃣ 清理解包过程产生的临时文件
7️⃣ 重新打包,生成最终 .pptx
并行处理优化
第五步”逐张修改内容”被特别标注为”如果有条件,多个幻灯片可以同时并行处理“。
每张幻灯片是独立的文件,互不干扰,完全可以多个任务同时进行,大幅提高效率。这体现了工程化思维——不只关心能不能做,还关心怎么做得更快。
🔧 scripts/ 目录:一套幕后工具
unpack.py 和 pack.py
这两个脚本是一对,负责 PPT 文件的”拆开”和”合上”。
- unpack.py 负责解压并整理格式,让内容更容易阅读和编辑
- pack.py 负责改完之后重新压缩,并在打包前做一次结构检查,确保文件合法
thumbnail.py
把 PPT 的每张幻灯片渲染成小图,拼成一张网格图,让 Claude 和用户快速看到所有版式,在正式修改之前先选好要用哪些布局。
soffice.py
对 LibreOffice 的封装,核心工作是在没有界面的情况下,把 PPT 文件自动转换成图片,用于后续的视觉检查。可以把它理解成一台”自动截图机器”——在后台自动执行,不需要手动操作。
validate.py 和 schemas/ 目录
schemas 目录里存放的是 Office 文件格式的官方规范文档。validate.py 在打包时用这些规范来校验生成的文件是否合法——就像检查合同有没有漏签名——确保最终输出的 .pptx 文件能被 PowerPoint 正常打开。
🔄 整体运行逻辑
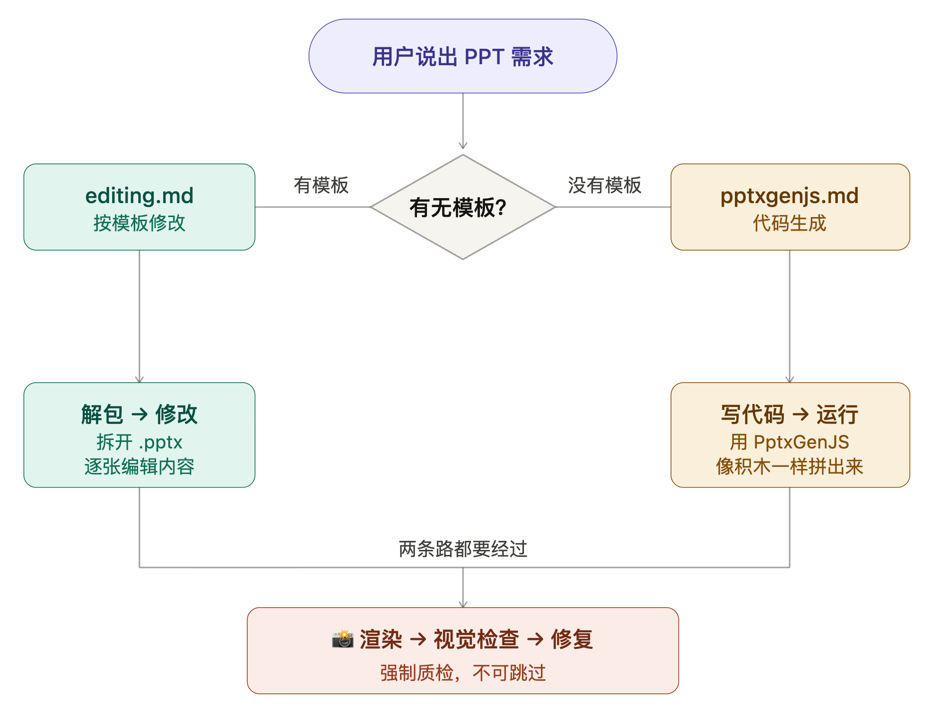
不管走哪条路,最后都必须过视觉检查这一关。
💡 这件事真正让我意外的地方
研究完这个技能的内部文件,最大的感受只有一个:
Claude 做出来的 PPT 质量上限,其实是写这份手册的人的认知上限。
配色方案、字号规范、禁止清单、踩坑记录——这些内容不是凭空生成的,是有人把大量的设计经验和失败教训一条一条写进去的。工具本身只是执行者,真正决定输出质量的,是背后那份”人类经验的结晶”。
这个道理不只适用于 PPT——你用 AI 做任何事情,结果的天花板,往往就是你告诉它什么。
如果你对如何安装和使用这个 PPTX 技能感兴趣,欢迎留言告诉我,后续可以出一篇实操教程。