微调大模型的悖论:引入新知识,可能助长『幻觉』
研究发现,大语言模型在微调时引入新知识不仅学习效率低,还可能导致『幻觉』现象
📌 导读: 大语言模型(LLMs)在预训练阶段已经积累了丰富的知识,那么,我们是否还需要通过微调去”教”它新的事实?一项最新研究指出:不加筛选地引入新知识进行微调,反而可能引发”幻觉”(hallucination)问题。
🔍 背景:微调的初衷与潜在风险
当前,许多大语言模型如 GPT、PaLM 等,都是在海量文本数据上进行预训练。这一阶段,它们已经掌握了大量世界知识。
然而,为了让模型在具体任务上表现更佳,研究人员通常会进一步使用人工构造的数据对其进行监督微调(supervised fine-tuning)。
📌 问题来了:
在微调过程中,如果加入了模型此前未见的新事实,模型是否真的”学会”了这些知识?或者,它只是在没有理解的情况下,学会了如何”编答案”?
🧪 实验设计:把知识分成四类
研究团队提出了一种名为 SliCK 的方法,用以衡量模型对不同知识的掌握程度。将问题分为四类:
| 类别 | 含义 | 示例 |
|---|---|---|
| 🟢 HighlyKnown | 模型总能答对 | “科学心灵运动的创始人是谁?” → 欧内斯特·霍姆斯 |
| 🟡 MaybeKnown | 偶尔答对 | “托莱多区的首府是哪里?” → 蓬塔戈尔达 |
| 🟠 WeaklyKnown | 仅在温度采样下答对 | “Scott McGrew 的职业?” → 新闻记者(但常答错) |
| 🔴 Unknown | 完全答不出 | “Benedict 位于哪里?” → Hubbard County(模型不知道) |
📉 关键发现一:新知识学得慢,副作用还大
研究发现:
- 模型在学习新知识(Unknown 类别)时非常缓慢;
- 一旦强行让它”学会”,整体性能反而下降;
- 严重时,会使模型在其他问题上出现”自信而错误“的回答(即幻觉)。
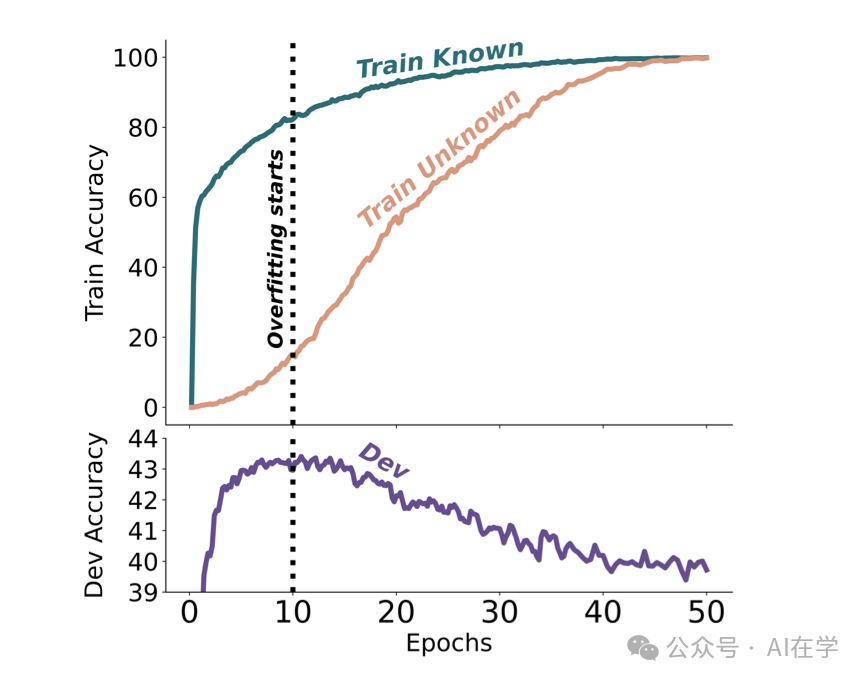
微调过程中,不同类别样本的拟合速度对比图
💡 微调过程中,不同类别样本的拟合速度对比显示:
最佳性能出现在模型主要掌握”已知”知识,而尚未完全学习”未知”样本的阶段。继续训练下去,反而会导致性能下滑。
⚠️ 关键发现二:新知识比例越高,性能越差
研究进一步比较了不同配比的微调数据集:
- 当加入的”未知”样本越多,模型的测试准确率越低;
- 而仅使用模型原本就”可能知道”的样本(MaybeKnown),反而表现更好;
- 若在训练中使用早停策略(early stopping),可有效防止过拟合与幻觉。
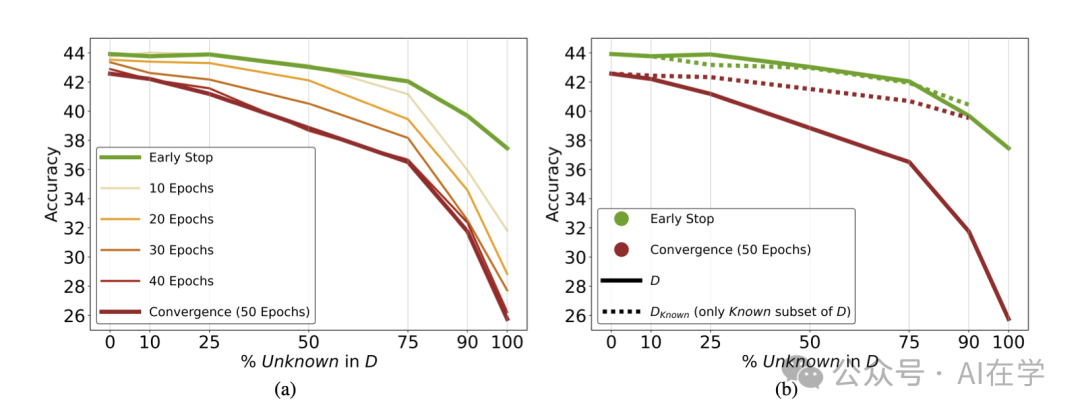
不同"未知知识"比例下的测试表现对比图
✅ 应对策略:不妨让模型”承认不知道”
研究还尝试了一种有趣的解决方案:
将未知样本的答案替换为 “I don’t know”,训练模型在不确定时学会拒答。
结果表明:
- 模型在”选择回答”的问题上,准确率反而显著提高;
- 并且,在训练时间拉长的情况下,准确率也更稳定。

将未知样本标签替换为'我不知道'(IDK)后的结果对比图
🧭 结语:微调,更应是”提效”而非”灌输”
研究揭示了一个重要而容易忽视的现象:
当前大模型的知识更多来自预训练,而微调的关键在于如何激活、组织与优化这些已有知识。
这意味着,微调不应一味追求”教新知识”,而应更谨慎地设计数据,避免引入过多”模型未掌握”的事实,尤其在缺乏配套机制时。
📎 参考链接
- 原论文:https://arxiv.org/abs/2405.05904
相关阅读: