👉 彻底搞懂时间序列异常检测:深度学习五大流派与核心论文盘点
📚 本文系统梳理了深度学习在时间序列异常检测(TSAD)中的应用,涵盖预测、重建、分类、表示学习和混合方法五大类别,并结合代表论文深入解析各方法的核心原理、优劣势及适用场景。⏱️✨


🔍 微信扫码或搜索「AI在学」关注公众号
1. 引言
1.1 为什么时间序列异常检测如此重要?
在当今数据驱动的世界中,时间序列数据无处不在:从工业传感器的毫秒级采样,到金融市场的逐笔交易,再到医疗设备的连续监护。在这些数据中, 异常往往意味着关键事件——可能是设备即将故障的预警信号、网络入侵的可疑行为、或是患者病情突变的征兆。
时间序列异常检测(Time Series Anomaly Detection, TSAD)的目标,就是在这些源源不断的数据流中,自动识别出偏离正常模式的观测点或子序列。与静态数据的异常检测不同,时间序列异常检测面临着独特的挑战:时间序列数据具有时间依赖性,当前时刻的观测值与历史值密切相关,简单的阈值判断往往无法捕捉到复杂的异常模式。
1.2 时间序列异常检测的独特性:与静态异常检测的区别
| 维度 | 静态异常检测 | 时间序列异常检测 |
|---|---|---|
| 数据特性 | 独立同分布样本 | 存在时间依赖性 |
| 异常形态 | 孤立的异常点 | 点异常、子序列异常、模式异常 |
| 上下文 | 全局统计特性 | 需考虑局部上下文和时序模式 |
| 检测难度 | 相对较低 | 需建模复杂的时序动态 |
1.3 单变量与多变量时间序列
时间序列数据根据变量维度可分为两类:
🔹 单变量时间序列(Univariate Time Series, UTS)
仅包含一个变量的时间序列,表示为有序序列:
\[X = (x_1, x_2, ..., x_t)\]其中 $x_i$ 表示时刻 $i$ 的观测值。UTS 的分析相对简单,只需考虑时间维度的依赖关系。
🔹 多变量时间序列(Multivariate Time Series, MTS)
包含多个相互依赖的变量,表示为向量序列:
\[X = (X_1, X_2, ..., X_t) = ((x_1^1, x_1^2, ..., x_1^d), (x_2^1, x_2^2, ..., x_2^d), ..., (x_t^1, x_t^2, ..., x_t^d))\]其中 $d$ 是变量维度数,$x_t^j$ 表示时刻 $t$ 第 $j$ 个变量的观测值。
MTS 的独特复杂性:
| 维度 | UTS | MTS |
|---|---|---|
| 依赖关系 | 仅时间依赖 | 时间依赖 + 变量间依赖 |
| 异常类型 | 时序异常 | 时序异常 + 跨维度异常 |
| 检测难度 | 相对较低 | 需建模复杂的时空耦合 |
MTS中的变量间往往存在空间依赖性,例如工业系统中温度与压力的相关性、服务器中CPU使用率与功耗的正相关性。当这些相关性被破坏时,即使单个变量正常,也可能发生跨维度异常。
1.4 典型应用场景
| 领域 | 检测目标 | 异常含义 |
|---|---|---|
| 🏭 工业物联网 | 传感器数据监测 | 设备故障预警,避免停机损失 |
| 💰 金融风控 | 交易行为分析 | 欺诈交易识别,资金安全保护 |
| 🏥 医疗健康 | 生理信号监护 | 心律失常检测,生命安全保障 |
| 🖥️ 智能运维 | 系统性能监控 | 服务异常发现,用户体验保障 |
| 🔒 网络安全 | 流量行为分析 | 入侵攻击检测,信息安全防护 |
| 🌊 自然灾害 | 环境数据监测 | 地震/洪水预警,灾害风险评估 |
1.5 为什么需要深度学习?
传统的时间序列异常检测方法(统计检验、阈值判断、简单机器学习)在以下场景面临困境:
| 挑战 | 说明 |
|---|---|
| 📊 高维度与复杂性 | 现代系统产生的多变量时间序列维度高、变量间关系复杂,传统方法难以捕捉非线性依赖 |
| ⏱️ 多尺度模式 | 异常可能在不同时间尺度(毫秒、小时、天)表现不同,手工设计特征难以覆盖 |
| 🔥 数据量爆炸 | 物联网设备每天产生 TB 级数据,需要自动化、可扩展的检测方法 |
| 🏷️ 标签稀缺 | 异常事件罕见且难以标注,监督学习方法往往不可行 |
深度学习凭借其强大的特征学习能力和非线性建模能力,能够自动从原始时间序列中学习复杂的时序模式和变量间关系,已成为时间序列异常检测领域的主流方法。
1.6 核心挑战
| 挑战 | 描述 | 影响 |
|---|---|---|
| ⏳ 时间依赖性 | 异常可能是连续子序列的异常模式,而非孤立点 | 增加检测复杂性 |
| 📏 多尺度性 | 异常可能在不同时间尺度表现不同 | 单一模型难以捕捉所有模式 |
| 🔄 概念漂移 | 正常行为的定义可能随时间变化 | 模型需要持续适应 |
| 🏷️ 标签稀缺 | 异常样本稀少且难以标注 | 限制监督学习方法的应用 |
| ⚡ 实时性要求 | 许多场景需要毫秒级响应 | 对模型推理速度提出高要求 |
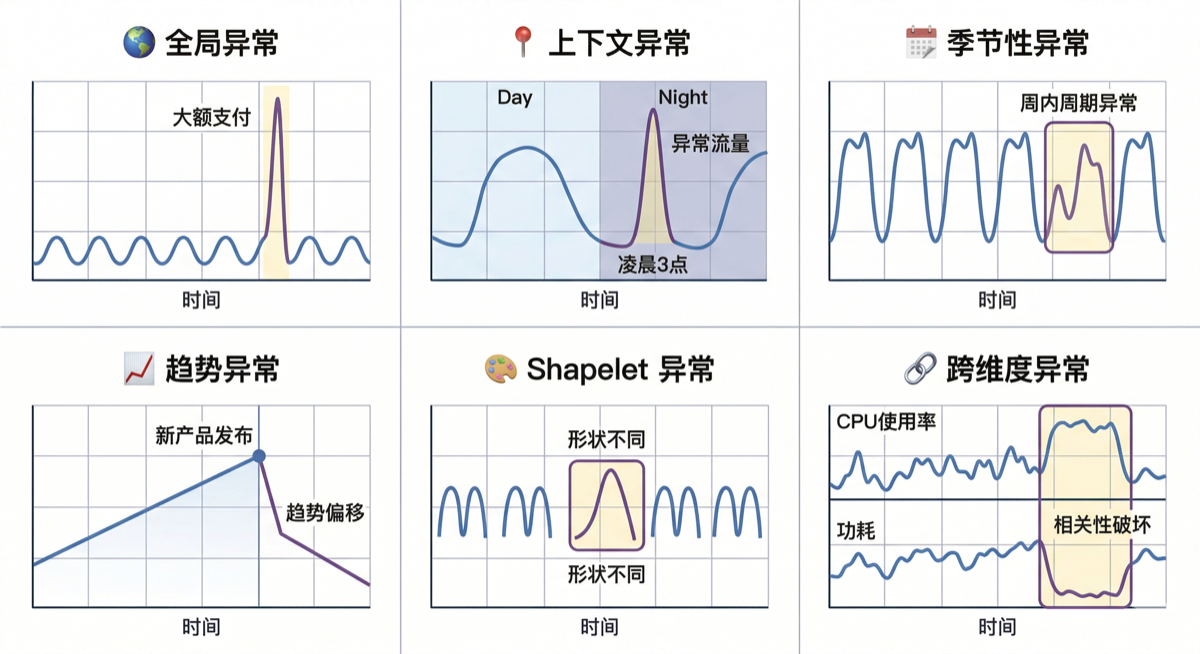
2. 时间序列的异常类型
根据异常在时间序列中的表现形态,可以分为以下六类:
| 类型 | 核心特征 | 典型示例 |
|---|---|---|
| 🌍 全局异常 | 与整个序列相比具有极端值 | 客户某天进行了异常大额支付 |
| 📍 上下文异常 | 在特定上下文中偏离预期 | 凌晨3点的网站流量与白天相当 |
| 📅 季节性异常 | 整体趋势正常,但周期性模式异常 | 餐厅客流呈现异常的周内周期 |
| 📈 趋势异常 | 数据发生永久性或长期趋势偏移 | 新产品发布后销售额断崖式下跌 |
| 🎨 Shapelet 异常 | 子序列的形状或模式与正常模式不同 | 股市在特定事件后呈现的异常波动形态 |
| 🔗 跨维度异常 | 多变量序列中变量间相关性被破坏 | CPU使用率与功耗的正相关性突然消失 |
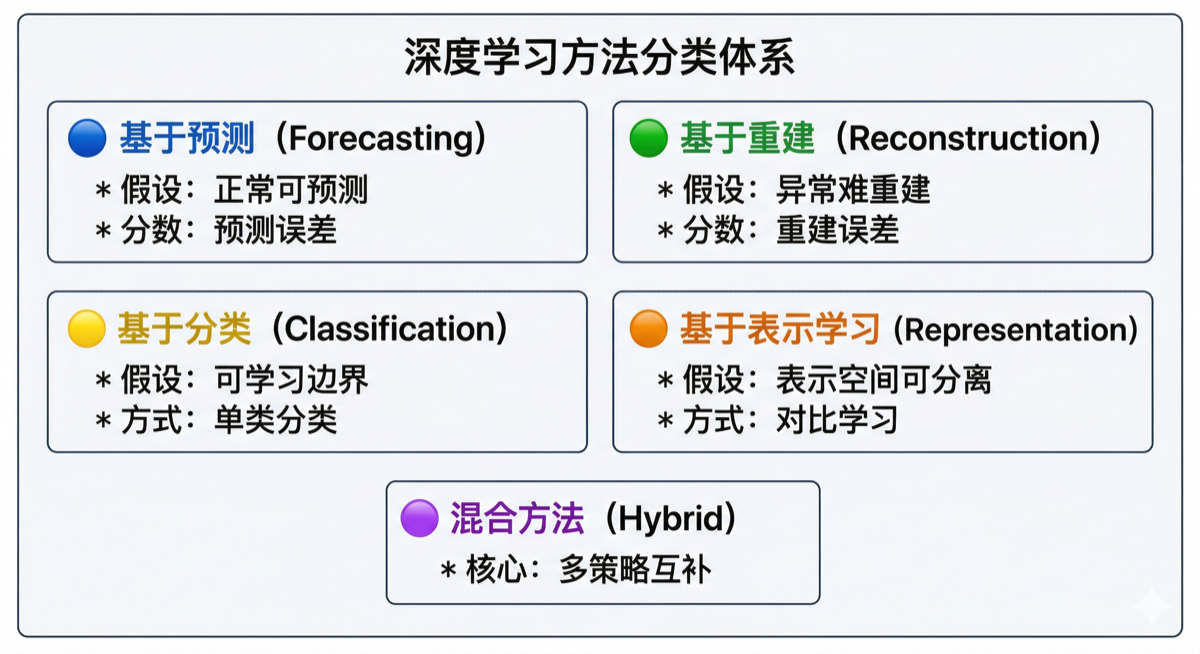
3. 深度学习方法分类体系
根据学习策略,深度学习方法可分为五大类别:
4. 🔵 基于预测的方法
4.1 核心原理
假设:正常时间序列具有内在的可预测性,异常事件会破坏这种可预测性,导致预测误差显著增大。
工作流程:
- 使用历史时间序列窗口 $X_{t-w:t-1}$ 作为输入
- 深度预测模型学习正常模式并预测下一时刻值 $\hat{x}_t$
- 计算预测误差 \(|x_t - \hat{x}_t|\)
- 误差超过阈值则判定为异常
数学表达:
\[AS_t = |x_t - \hat{x}_t| > \text{threshold}\]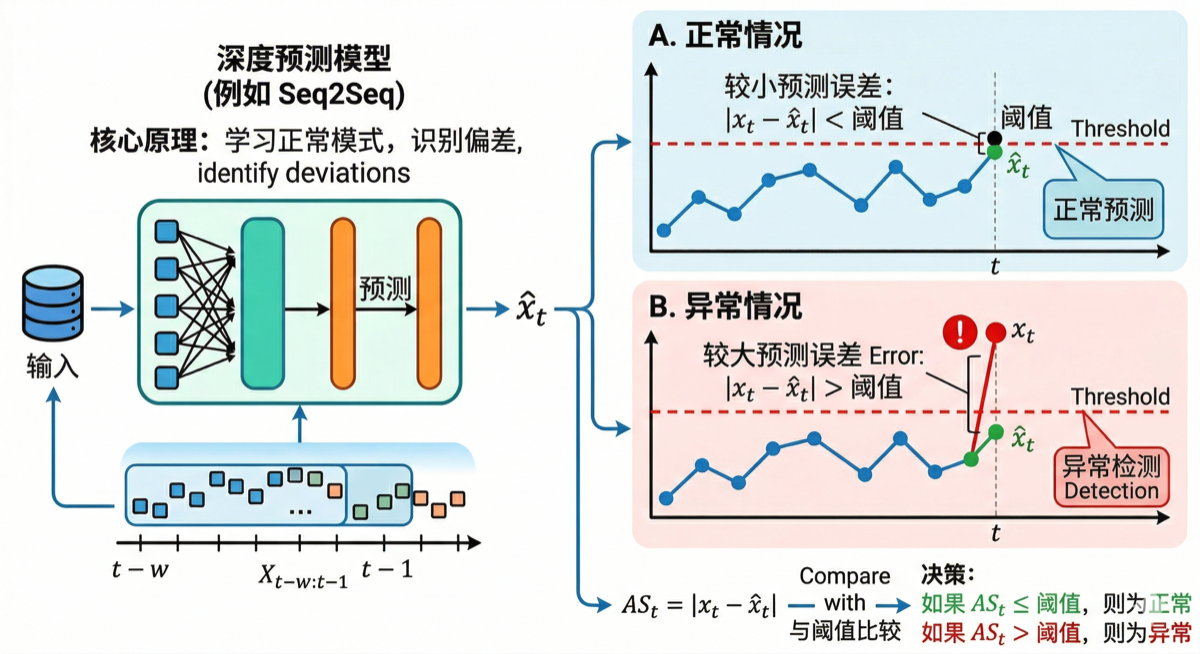
4.2 优劣势
| ✅ 优势 | ❌ 局限 |
|---|---|
| 实时性好,可在线检测 | 难以预测快速变化的序列 |
| 单次前向传播即可预测 | 对突发异常响应可能滞后 |
| 适合周期性强的数据 | 复杂模式学习能力有限 |
4.3 代表性论文
📄 DeepAnT: A Deep Learning Approach for Unsupervised Anomaly Detection in Time Series
🔗 https://www.dfki.de/fileadmin/user_upload/import/10175_DeepAnt.pdf
5. 🟢 基于重建的方法
5.1 核心原理
假设:正常数据可以被压缩到低维潜在空间并有效重建,异常数据由于偏离训练分布,重建误差较大。
与预测方法的关键区别:
| 方法 | 输入 | 输出 | 信息利用 |
|---|---|---|---|
| 预测 | $X_{t-w:t-1}$ | $\hat{x}_t$ | 仅历史信息 |
| 重建 | $X_{t-w:t}$ | $\hat{X}_{t-w:t}$ | 完整窗口信息 |
数学表达:
\[AS = ||X - \text{Decoder}(\text{Encoder}(X))||^2\]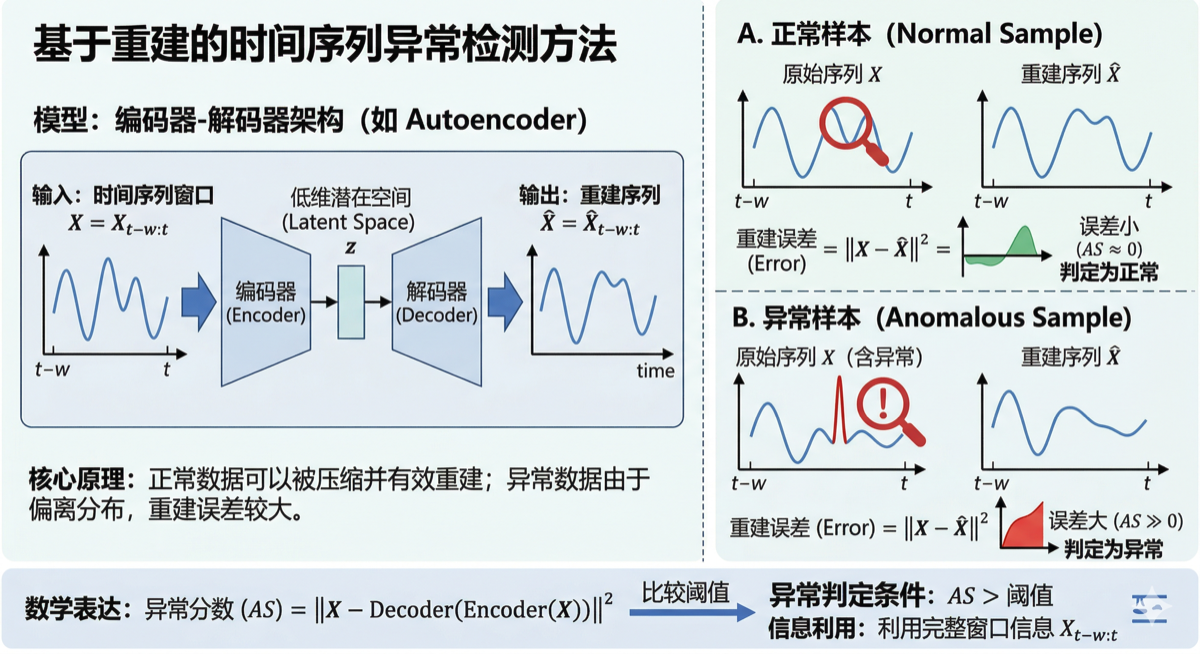
5.2 主要技术路线
| 技术 | 核心思想 |
|---|---|
| Autoencoder (AE) | 学习数据的压缩表示,最小化重建误差 |
| VAE | 将输入编码为概率分布,引入正则化 |
| GAN | 生成器与判别器对抗训练 |
| Transformer | 利用自注意力捕捉全局依赖进行重建 |
5.3 优劣势
| ✅ 优势 | ❌ 局限 |
|---|---|
| 利用完整窗口信息,精度高 | 有轻微检测延迟 |
| 适合变化快速的序列 | 模型通常较复杂 |
| 可检测子序列异常 | 训练需要更多计算资源 |
5.4 代表性论文
📄 LSTM-based Encoder-Decoder for Multi-sensor Anomaly Detection (EncDec-AD)
🔗 https://arxiv.org/abs/1607.00148
6. 🟡 基于分类的方法
6.1 核心原理
基于分类的方法将异常检测视为二分类问题(正常 vs 异常)或单类分类问题(仅学习正常类的边界)。
两种范式对比:
| 范式 | 训练数据 | 适用场景 |
|---|---|---|
| 二分类 | 正常 + 异常样本 | 有足够标注异常样本 |
| 单类分类 | 仅正常样本 | 异常样本稀少或缺失 |
数学表达(单类分类):
\[f(X) = \begin{cases} \text{正常}, & \text{if } X \in \mathcal{N} \\ \text{异常}, & \text{if } X \notin \mathcal{N} \end{cases}\]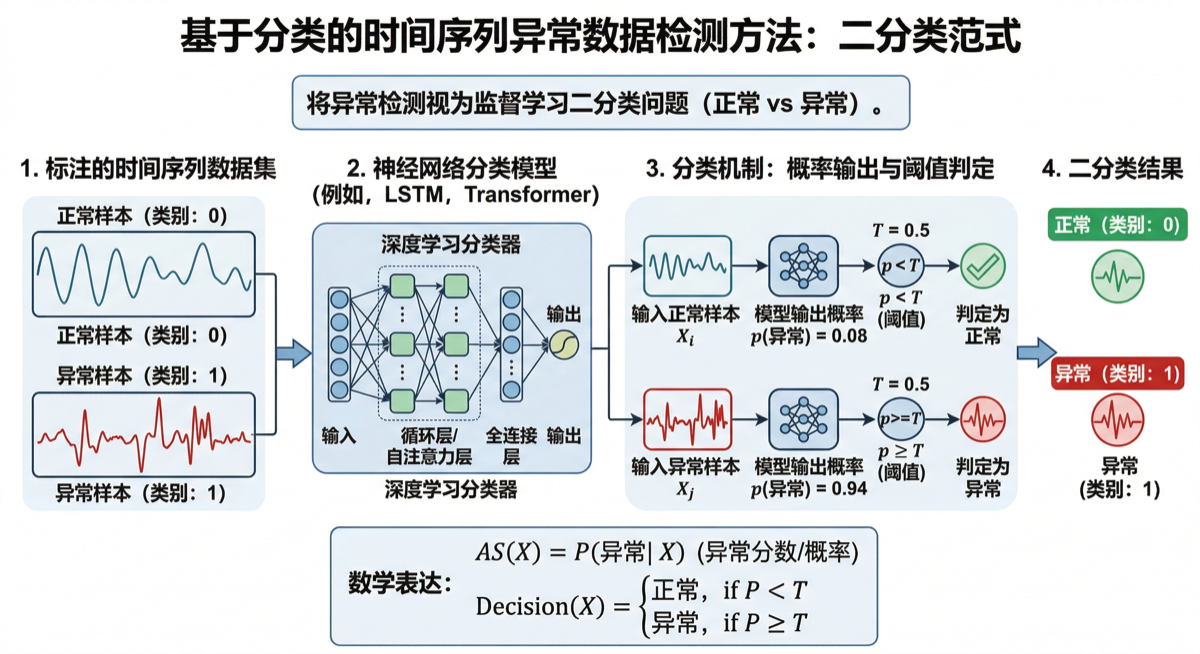
6.2 主要技术路线
| 技术 | 核心思想 |
|---|---|
| Deep SVDD | 学习将正常数据映射到超球中心 |
| OC-SVM | 寻找最大间隔超平面分离正常数据 |
| 分类网络 | 端到端训练二分类器 |
| 度量学习 | 学习距离度量使正常样本聚集 |
6.3 优劣势
| ✅ 优势 | ❌ 局限 |
|---|---|
| 直接优化分类目标 | 需要标签数据(至少正常样本) |
| 可解释性强(决策边界) | 异常样本不足时效果受限 |
| 可结合传统分类技术 | 对概念漂移敏感 |
6.3 代表性论文
📄 Deep One-Class Classification (Deep SVDD)
🔗 https://proceedings.mlr.press/v80/ruff18a.html
💻 https://github.com/lukasruff/Deep-SVDD-PyTorch
7. 🟠 基于表示学习的方法
7.1 核心原理
核心思想:不直接优化预测或重建误差,而是专注于学习高质量的、具有判别性的特征表示。在良好的表示空间中,正常样本会形成紧凑的簇,而异常样本会远离这些簇。
工作流程:
- 使用对比学习等自监督方法学习表示
- 正样本对:语义相似的样本(相邻时间戳、同一序列的增强版本)
- 负样本对:语义不同的样本(不同序列、注入异常的样本)
- 在表示空间中,远离正常簇的样本判定为异常
学习目标:
\[\mathcal{L} = -\log \frac{\exp(\text{sim}(z_i, z_j^+)/\tau)}{\sum_{k} \exp(\text{sim}(z_i, z_k)/\tau)}\]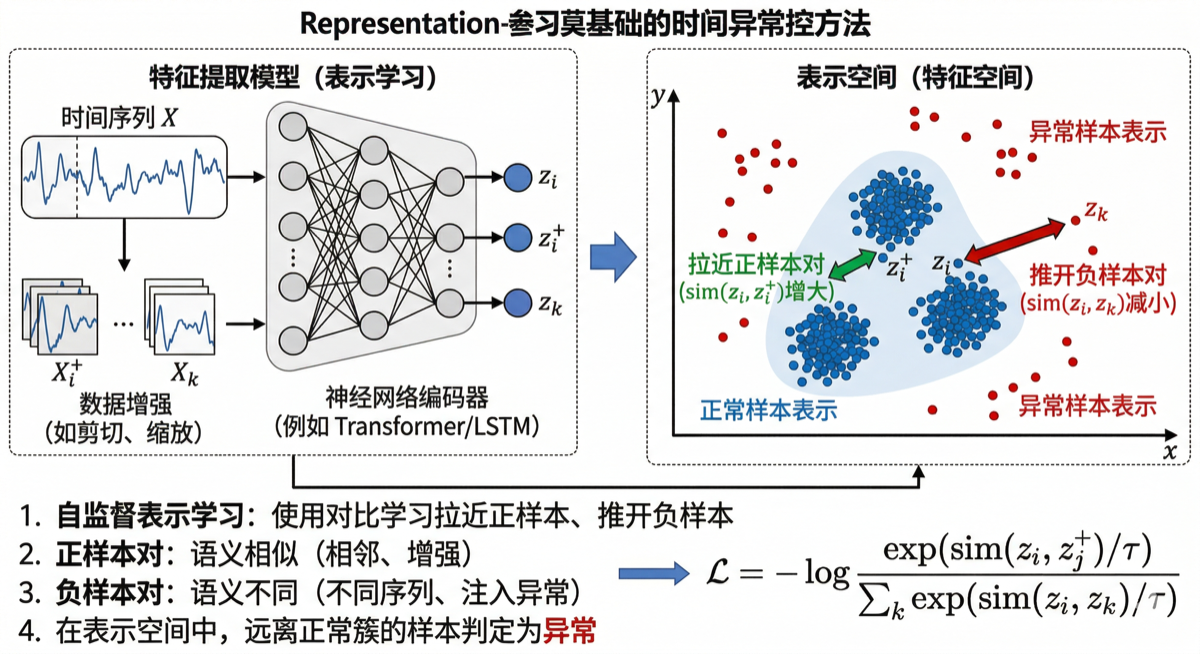
7.2 优劣势
| ✅ 优势 | ❌ 局限 |
|---|---|
| 学习到的表示可迁移 | 训练复杂度较高 |
| 对噪声更鲁棒 | 需要精心设计对比任务 |
| 无需标签数据 | 表示质量依赖数据增强策略 |
7.3 代表性论文
📄 TS2Vec: Towards Universal Representation of Time Series
🔗 https://arxiv.org/abs/2106.10466
💻 https://github.com/yuezhihan/ts2vec
8. 🟣 混合方法
8.1 核心原理
核心思想:单一策略有局限性,结合多种策略可互补。
常见互补组合:
| 组合 | 互补优势 |
|---|---|
| 预测 + 重建 | 预测捕捉未来趋势,重建捕捉全局信息 |
| 图学习 + 时序建模 | 同时捕捉空间(变量间)和时间依赖 |
| 距离 + 表示学习 | 结合判别能力和表示能力 |
多任务学习框架:
\[\mathcal{L}_{\text{total}} = \lambda_1 \mathcal{L}_{\text{forecast}} + \lambda_2 \mathcal{L}_{\text{recon}} + \lambda_3 \mathcal{L}_{\text{classification}}\]8.2 优劣势
| ✅ 优势 | ❌ 局限 |
|---|---|
| 综合利用多种信号 | 模型复杂度高 |
| 适合复杂的高维时间序列 | 需要调节多个超参数 |
| 通常精度更高 | 训练时间和计算资源需求大 |
8.3 代表性论文
📄 Multivariate Time-series Anomaly Detection via Graph Attention Network (MTAD-GAT)
🔗 https://arxiv.org/abs/2009.02040
💻 https://github.com/ML4ITS/mtad-gat-pytorch
9. 总结
五种深度学习方法的核心差异对比:
| 方法 | 核心假设 | 关键优势 | 主要局限 | 参考代表论文 |
|---|---|---|---|---|
| 🔵 基于预测 | 正常可预测 | 实时性好 | 难预测快速变化 | DeepAnT |
| 🟢 基于重建 | 异常难重建 | 精度高 | 有轻微延迟 | EncDec-AD |
| 🟡 基于分类 | 可学习决策边界 | 可解释性强 | 需设计边界 | Deep SVDD |
| 🟠 基于表示学习 | 表示空间可分离 | 鲁棒性强 | 训练复杂 | TS2Vec |
| 🟣 混合方法 | 多策略互补 | 综合能力好 | 模型复杂 | MTAD-GAT |
每种方法都有其适用场景和局限性。在实际应用中,建议根据数据特性、标签可用性和任务需求选择合适的方法。
参考文献
- 📄 Deep Learning for Time Series Anomaly Detection: A Survey
- 📄 DeepAnT: A Deep Learning Approach for Unsupervised Anomaly Detection in Time Series
- 📄 LSTM-based Encoder-Decoder for Multi-sensor Anomaly Detection (EncDec-AD)
- 📄 Deep One-Class Classification (Deep SVDD)
- 📄 TS2Vec: Towards Universal Representation of Time Series
- 📄 Multivariate Time-series Anomaly Detection via Graph Attention Network (MTAD-GAT)