别再瞎折腾 RAG 了:LLM Wiki 才是个人知识库的终局
Andrej Karpathy 提出的 LLM Wiki 概念,如何降维打击传统 RAG,打造全自动进化的知识库

每个人都在谈论大模型时代。你可能也像我一样,在微信收藏夹、Notion 或电脑硬盘里,攒了成百上千篇 PDF 论文、行业报告和网页剪藏。
为了消化这些“数字资产”,我们开始折腾 RAG(一种让 AI 读你的文件来回答问题的技术),把文件丢给 ChatGPT、Claude 或 NotebookLM。
但你有没有发现,这些工具存在一个一旦看穿就再也无法直视的巨大漏洞?
你上传了文件,向 AI 提问,AI 检索并回答了你——这很好。
但到了明天,你问了一个类似的问题,AI 又从头开始重新检索。
没有任何东西被保存,没有任何知识被沉淀。每一次提问,AI 都从“零”开始。
为了彻底解决这个痛点,AI 圈顶级大牛、前特斯拉 AI 总监、OpenAI 联合创始人 Andrej Karpathy 提出了一个全新的知识管理范式:LLM Wiki。
今天这篇文章,就聊透什么是 LLM Wiki,它凭什么能降维打击传统 RAG,以及如何用它打造一个全自动进化的知识库。
01|传统 RAG 的死穴:为什么它永远是“新来的”?
想象一下,你雇了一位顶尖科学家帮你研究课题,把手头 100 篇核心论文全打包交给了他。
但在传统 RAG 模式下,这位科学家仿佛患有“短期失忆症”:每次你推门进去问他问题,他都表现得像第一天上班——必须当着你的面,把那 100 篇论文重新翻一遍,现场切片、现场缝合。
明天你再来问类似的问题,他还要再翻一遍。
他永远没有“读完、消化、合上书”的那一天。每一次提问,他都回到起点。
这种传统 RAG 模式,本质上就是低效的“现翻小抄”。仔细推敲,会发现它有三个硬伤:
| 痛点 | 传统 RAG 的表现 | 实际体验 |
|---|---|---|
| 记忆 | 无状态,每次归零 | 第 1 次和第 100 次提问,AI 面对的是同一堆原始文件 |
| 关联 | 知识点各自孤立 | 问题涉及多篇文档,AI 每次都要重新现织一张网 |
| 效率 | 原始文件噪音极高 | 文档里的废话、广告、重复段落,每次检索都要一并处理 |
为了打破这种“天天做新兵”的僵局,Karpathy 提出了 LLM Wiki 的概念。
核心思路是:让大语言模型从“答题工具”变成“知识管家”——把你的原始资料,直接整理成一套结构化的 Wiki 知识库。
以前,无论你在 Obsidian 或 Notion 里存了多少资料,都必须由你本人苦哈哈地阅读、分类、打标签、连双链——你不仅是知识的输入者,还是整个数据库的清洁工。
现在,AI 接管了所有内容整理工作。你只需要把原始素材扔进文件夹,AI 就会通读资料,提炼干货,自动织成一张有条不紊的知识网。

02|核心逻辑:让 AI 读一遍,然后替你整理好
在这个新范式下,AI 终于告别了“短期失忆症”。
每当你丢进来一篇新资料(PDF、网页剪藏、会议记录……),AI 只执行一次动作:通读原始文件,然后把它精编和重构。
读完之后,杂乱的原始素材就变成了高度精炼、打满双向链接的纯文本 Wiki 页面。
- 原始资料(raw/) = 🛠️ 原始素材,只读不改,是你的最终事实来源
- AI(LLM) = ⚙️ 知识主编,负责通读、理解、拆解和重构
- Wiki 文件夹 = 📦 知识脱水成品,已经组织好、可直接高效调用的知识网
从此以后,无论是你还是 AI 想要调用知识,都不需要再去翻那些臃肿的原始文件,而是直接在已经织好的 Wiki 里运转。
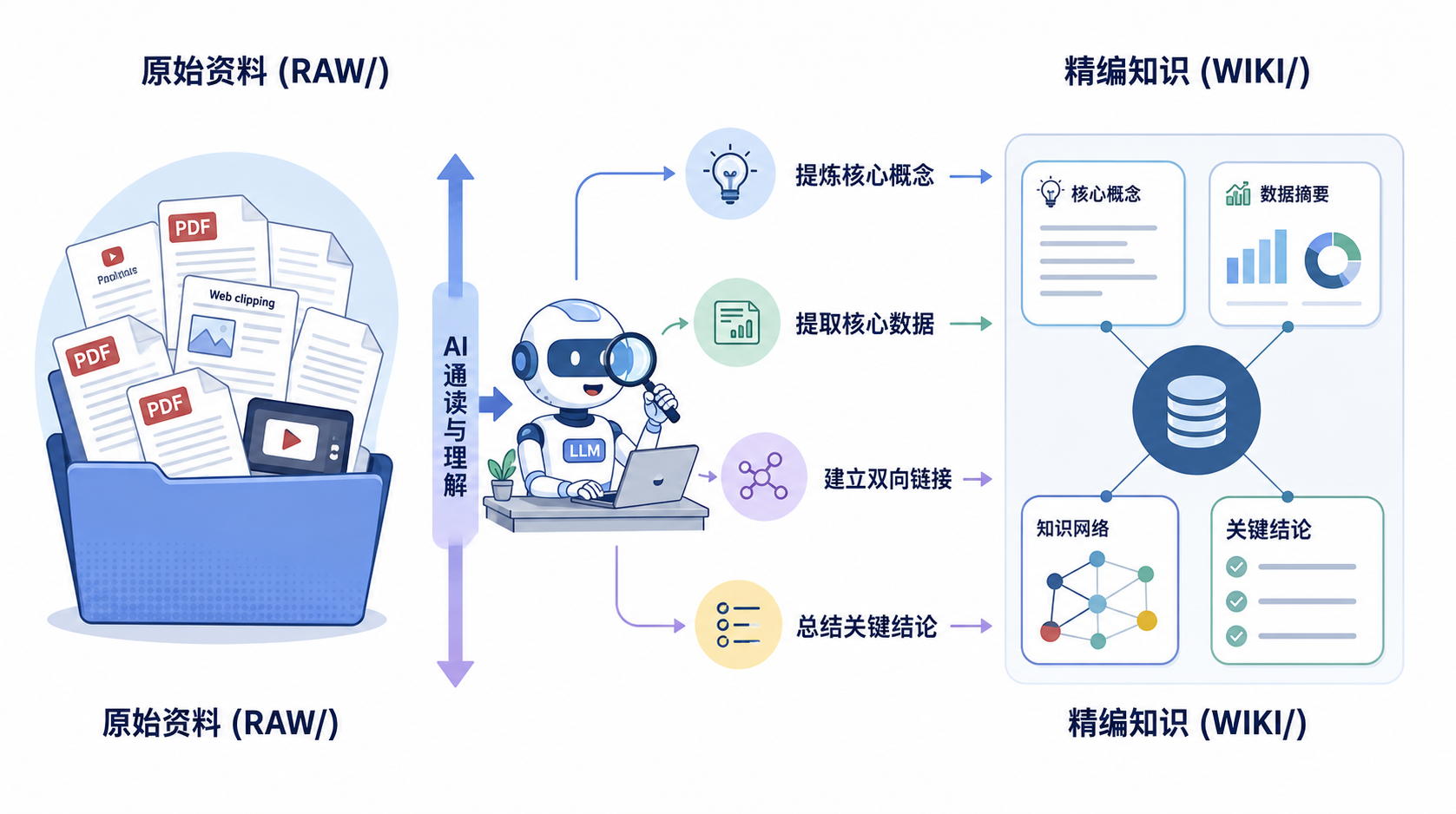
03|它是如何运转的?极简的“三层架构”
这个系统的美妙之处在于极其简单。只要会在电脑上新建文件夹,你就能看懂。一共只有三层:
1
2
3
4
📁 My_Second_Brain/
├── 📁 raw/ ← 原始素材库(只读,你的绝对事实来源)
├── 📁 wiki/ ← Wiki 知识库(AI 自动维护的精编成果)
└── 📄 CLAUDE.md ← 系统全局规则(你给 AI 秘书的“打工守则”)
🧱 Layer 1:原始素材库(raw/)
你的输入端。论文、博客、视频转录文本,通通扔进来。 📌 绝对只读——AI 可以看,但永远不能改。用于后续的审计与追溯。
🧠 Layer 2:Wiki 知识库(wiki/)
完全由 Markdown 文件组成的网状结构,由 AI 负责写入和维护。里面包含:
- Index 页面:整个知识库的全局总览
- 概念页面:比如独立的
[[Transformer架构]]、[[用户增长模型]]页面 - 更新日志:AI 自动记录每次整理了什么
📜 Layer 3:指令配置(CLAUDE.md)
用自然语言写给 AI 的“工作守则”:Wiki 格式如何统一?发现新概念时怎么建立 [[双向链接]]?遇到矛盾信息怎么处理?一次写好,全程生效。

04|三大高光功能,让知识库真正“活”起来
🔄 1. 知识自动滚雪球(Ingest)
塞进一篇新文章,AI 不是把它存着吃灰。它会读懂内容,顺藤摸瓜,自动更新已有的 Wiki 页面,把新概念链接到旧知识上。
资料越积越多,Wiki 不会越来越乱,反而因为持续重构变得越来越精炼。
⚠️ 2. 自动发现“打架”的内容(Flagging)
如果新传进来的资料,跟两周前上传的报告在数据或观点上存在矛盾,AI 在更新 Wiki 时会立刻弹出标记提醒你:“这两份文件观点冲突,请注意甄别。”
而不是悄悄选一个当作正确答案。
💾 3. 对话成果一键固化(Save)
以前你和 AI 展开一场深度讨论,关掉对话框,所有火花就消失了。
现在只需要一个指令(如 --save),AI 就会把这次对话的核心结论直接沉淀为 Wiki 的一个新页面,永久留存。
05|结语:把体力活留给 AI,把思考留给自己
很多人喜欢用 Obsidian 或 Notion 搞“笔记装修”,花大量时间分类、打标签、建目录,最后陷入“差生文具多”的怪圈——收集了一堆,一问三不知。
LLM Wiki 的本质,是一次分工的重新划定:
分类、打标签、总结、重构这些无聊的体力活,本就应该属于 AI。 人类唯一的职责,是寻找高质量的源头,以及基于提炼后的知识进行真正的深度思考。
这不只是一个技术工具的变革,更是一场个人认知效率的重新洗牌。
你准备好让 AI 帮你打造一个持续进化的“知识库”了吗?
如果你想看如何用 Claude Code + Obsidian 手把手从零搭建这套系统,点赞告诉我,下期安排!