💡 AI Agent 核心技术:一文读懂 Context Engineering 及主要做法
深入解析 AI Agent 核心技术 Context Engineering:从压缩替换、多层级记忆、子智能体到按需加载,系统性讲解如何在有限上下文窗口中让 LLM 看到最有价值的信息。
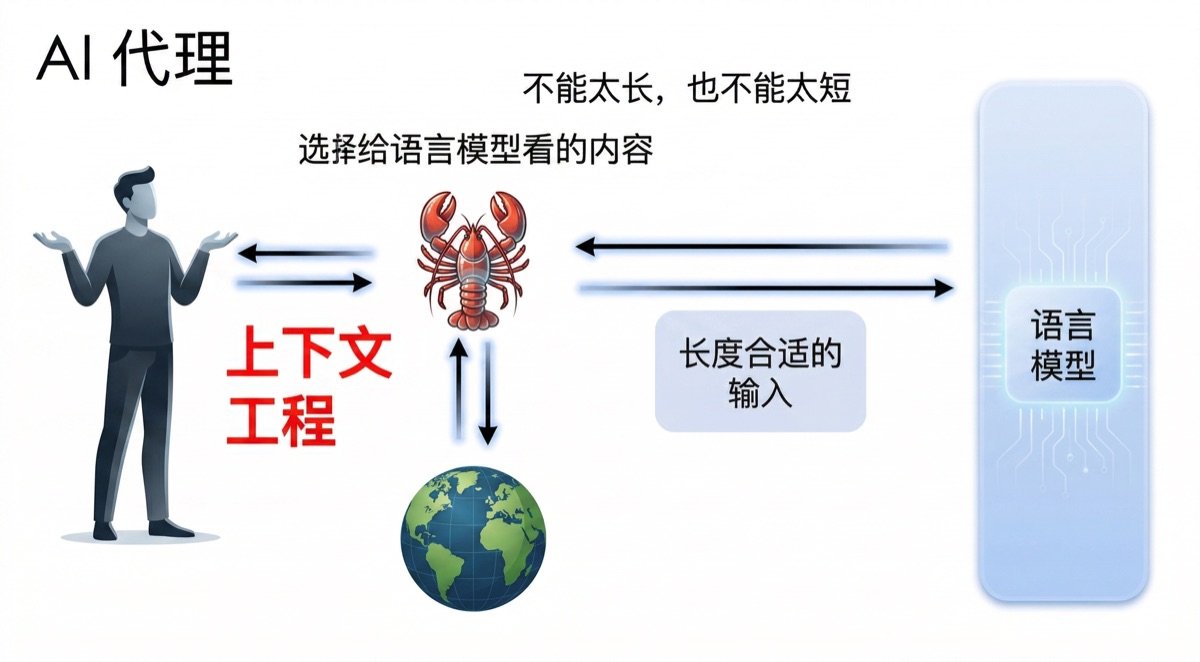
在开发复杂的 AI Agent 系统时,开发者面临的核心挑战之一,就是如何精准管控大语言模型(LLM)的输入长度。对于大语言模型(LLM)而言,上下文(Context)并非越长越好,也不是越短越妙,这背后涉及了一个微妙的平衡。
为了让大语言模型能够处理长程任务而不“断片”或“迷失”,上下文工程(Context Engineering) 成为了 AI Agent 不可或缺的技术底层。
所谓上下文工程,就是开发者围绕“该给模型看什么”这个问题,所采用的一系列做法。 它不是简单地“把更多信息塞给模型”,也不是粗暴地“删掉旧记录”,而是通过一系列手段对信息进行处理,在每一轮推理中让模型看到的都是最相关、最精炼的信息。
在此系统中,AI Agent 扮演着大语言模型的“经纪人”或“守门员”的角色,通过各种预设规则或自主决策,确保传递给“大脑”(LLM)的每一条信息都是精确且高效的。
一、❓ 为什么需要上下文工程
上下文工程的核心目标是寻找大语言模型输入的“黄金比例”。如果管理不当,系统会面临以下来自 LLM 特性的极端风险:
1. 不能太长:避免 LLM 的溢出与精度衰减
- 窗口限制:每个大语言模型(LLM)都有其固定的上下文窗口(Context Window),一旦 Token 数量超限,模型将无法读取更早的信息。打个比方:如果模型的窗口是 1 万个 Token,而你传给了它 15,000 个 Token,前面的 5,000 个就会被丢弃,里面所蕴含的信息模型也就无从知晓了。
- 推理精度稀释:研究显示,当输入的上下文包含大量冗余信息时,LLM 的推理精度会大幅下降(即所谓的 “Lost in the Middle” 现象)。这意味着信息过多会分散模型的注意力,导致生成的内容不精确,甚至产生幻觉。
2. 不能太短:确保 Agent 逻辑的连贯性
- 信息缺失:LLM 本质上是在做“文字接龙”。如果提供的信息过于简略,LLM 就会丢失之前的任务目标、中间执行结果或环境状态,导致模型无法准确预测下一个步骤,最终造成 Agent 的任务逻辑断裂。
二、📐 核心公式
为了更直观地理解 Context Engineering 如何管理 LLM 输入,我们可以通过数学公式来对比有无上下文工程的差异。
1. 无上下文工程
在没有干预的情况下,上下文只是将所有的用户输入和模型的输出进行线性拼接。
初始化状态:
\[\begin{aligned} & I_1 \leftarrow \text{用户输入 (User Input)} \\ & C_1 \leftarrow \text{空,即初始上下文内容 (Context) 为空} \end{aligned}\]执行逻辑如下:(每一步都重复这个循环)
\[\begin{aligned} & O_t = LLM(I_t, C_t) \\ & C_{t+1} \leftarrow C_t \mid I_t \mid O_t \end{aligned}\]⚠️ 核心痛点: 符号“$\mid$”代表简单的拼接。随着循环进行,上下文 $C_t$ 的长度会迅速膨胀,最终超出大语言模型的窗口上限,或因冗余过多直接拖垮推理精度。
2. 有上下文工程
引入上下文工程后,系统不再进行简单的拼接,而是通过一个处理函数 $F$ 对信息进行智能转化与精炼。
初始化状态:
\[\begin{aligned} & I_1 \leftarrow \text{用户输入 (User Input)} \\ & C_1 \leftarrow \text{空,即初始上下文内容 (Context) 为空} \end{aligned}\]执行逻辑如下:(每一步都重复这个循环)
\[\begin{aligned} & O_t = LLM(I_t, C_t) \\ & C_{t+1} \leftarrow F(C_t, I_t, O_t) \end{aligned}\]❓ 这个 $F$ 到底是什么? 它是开发者设计的处理逻辑,负责对信息进行精炼、转化和存储,确保传递给 LLM 的内容始终维持在“黄金长度”。
三、🛠️ 核心技术手段详解
为了实现处理函数 $F$,开发者可以采用多种技术手段。这些手段可以是基于规则的,也可以是由 Agent 自主做主的。下面介绍几种最常见的做法。
🗜️ 压缩与替换
当内容开始臃肿时,系统会优先执行物理瘦身。
- 压缩(对话总结):通过预设规则或模型调用,定期将琐碎的对话历史总结成摘要。例如:当历史对话超过一定长度(如 10 轮)时,系统自动触发总结逻辑,将之前的对话压缩成摘要。其核心目标是在保留关键里程碑的前提下,缩短文本长度。
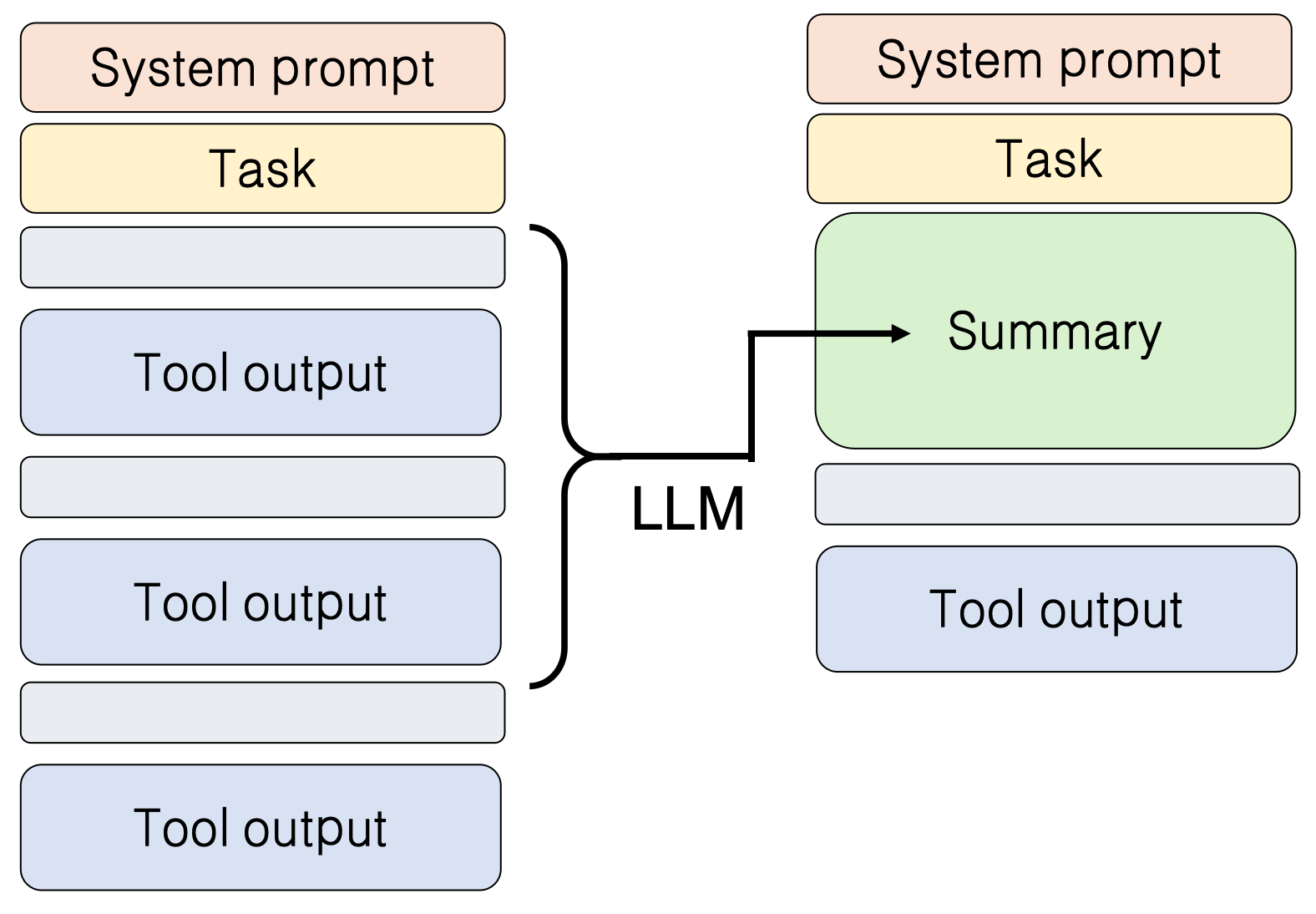
- 替换(结果替换):另一个出乎意料的方法是,针对工具返回的冗长结果(如超长文本内容),直接将其替换为一个占位符:“这里曾经有个 Tool output”。神奇的是,实验表明这种方式居然能有效维持 LLM 的逻辑连贯性。
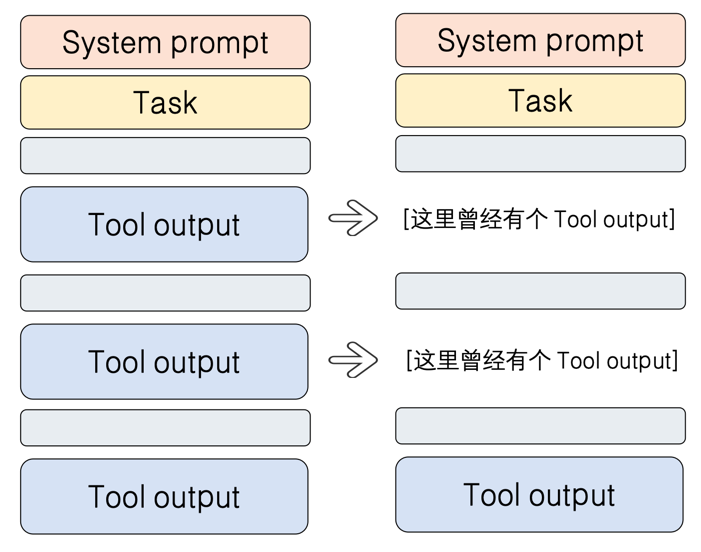
当然,这些方法也并非完美无缺。压缩过狠会导致“轨迹延长”——如果关键细节被抹除,LLM 就会“忘记”自己已经做过某些动作,从而反复执行同一任务,形成无效循环。
关于压缩与替换策略的有效性,可参考论文:
When Less is More: On the Cost-Effectiveness of Observation Masking in LLM Agents
https://arxiv.org/abs/2508.21433
🧠 多层级记忆架构
如果把所有历史记录都塞给模型,它难免会“看花眼”。还有一种做法是把信息分成两档:模型“眼前”只放最核心的内容,剩下的先存到外部“仓库”里,需要的时候再调出来。
- P (Prompt) 活跃记忆:筛选出的核心信息,实时输入给 LLM,保证高精度推理。
- M (Storage) 长期记忆:所有需要存储的信息被存储在外部数据库中。
- 按需加载:通过预设的检索逻辑,决定何时从长期记忆中取回片段、注入到活跃记忆中。
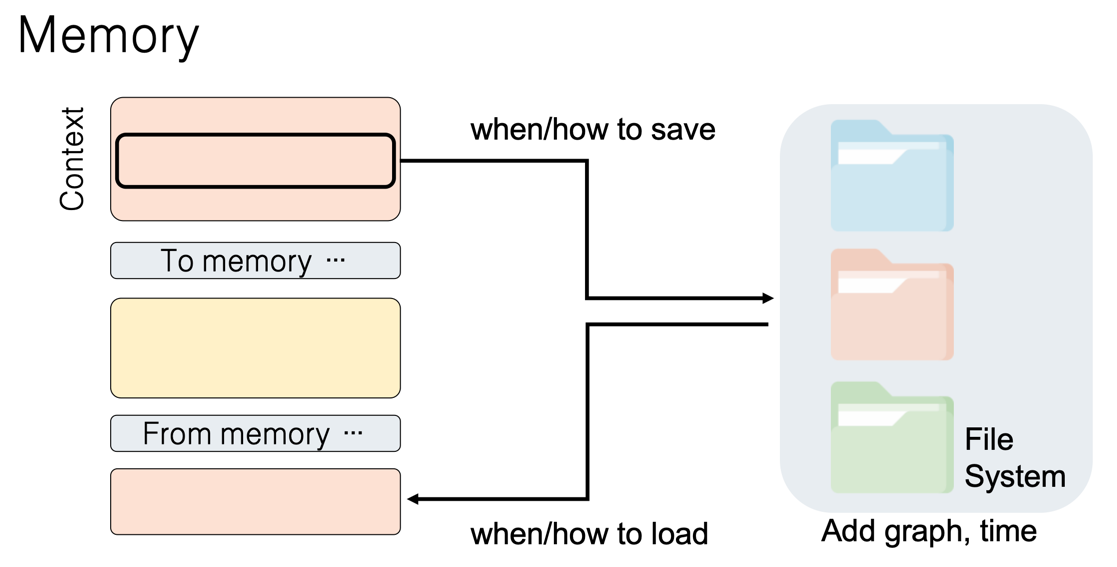
在这一架构中,具体怎么存、怎么读,仍是一个值得深入研究的问题。 这种精细化的管理决定了 Agent 是否能在庞大的历史数据中精准定位到当前任务所需的“那一块”拼图。
📐 进阶公式:更精准的上下文管理
为了更精细地描述上述记忆机制,我们需要将上下文 $C$ 拆解为 $P$ 与 $M$ 两个部分。此时,系统演进为:
状态:
\[C_t = \{P_t, M_t\}\]执行与更新逻辑:
\[\begin{aligned} & O_t = LLM(I_t, P_t) \\ & C_{t+1} \leftarrow F(C_t, I_t, O_t) \end{aligned}\]在这个公式中,我们可以清晰地看到:
- 输入变化:LLM 的输入不再是完整的 $C_t$,而是经过筛选后的 $P_t$。
- 状态更新:当执行 Load Memory 时,系统从 $M$ 中提取信息更新至 $P$;当执行 Save Memory 时,系统则将信息从当前交互持久化到 $M$ 中。
这两个公式其实顺带厘清了一个实际中常被混用的问题:Context 和 Prompt 到底是什么关系?简单来说,$C$ 是 Agent 的全部状态(活跃记忆 + 外部存储),可以理解为它的“全部阅历”;而 $P$ 只是当前真正输入给 LLM 的那一部分。Context 不一定全部成为 Prompt,上下文工程的核心,就是怎么把“全部阅历”高效地提炼成“当前该看的精华”。
关于内存化操作系统级别的记忆管理,可参考论文:
Memory OS: An Operating System for LLM Agents
https://arxiv.org/abs/2506.06326
👥 子智能体
除了把信息整理归类,还可以换个思路:把大块任务拆出去独立执行,主 Agent 只看最终结果,过程信息不会涌入主上下文。
- 委派机制:主 Agent 派发任务给临时的“子智能体”。子智能体在执行时产生的海量过程 Token 只留在其私有空间。
- 瞬时清理:子任务结束后,主 Agent 仅接收一行结果,中间的数千个过程 Token 被瞬间抹除。这会产生显著的锯齿状 Token 效应。
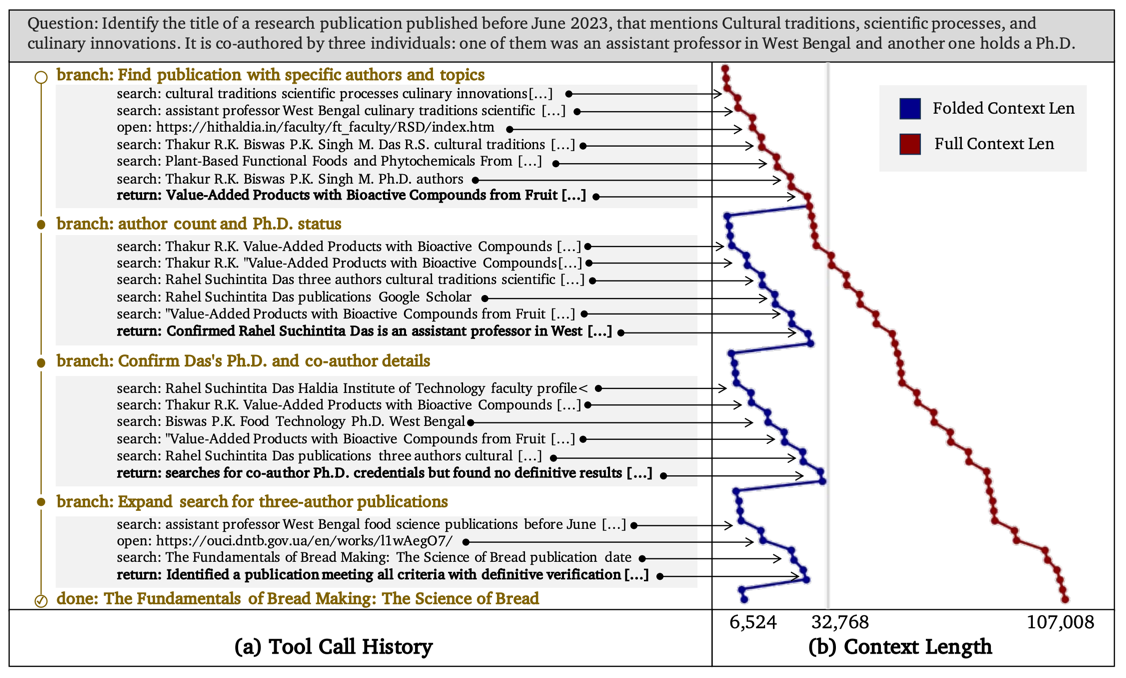
如上图所示,我们可以观察到明显的 “锯齿状” Token 效应:
- 红线(Full Context):如果不使用子智能体,所有搜索和执行过程的 Token 会不断累积,最终飙升到 107,008 个。
- 蓝线(Folded Context):主 Agent 每开启一个子智能体(图中左侧的 branch),Token 开始累积(上升);一旦子任务结束并返回结果,中间冗长的搜索记录被瞬间抹除,Context 长度瞬间回落(下降)。
结论:子智能体的本质是让模型在处理海量信息时,只保留“结论”,而忘掉“过程”,从而将 context 维持在安全区间。
相关技术研究可参考论文:
Scaling Long-Horizon LLM Agent via Context-Folding
https://arxiv.org/pdf/2510.11967
🎯 智能预过滤与按需加载
前面提到的压缩、替换、子智能体等手段,本质上都是在信息已经进入上下文之后“事后清理”。但如果我们追问一个更根本的问题:这些臃肿的 context 究竟是从哪里来的?
有研究者对 Agent 对话历史中的 token 来源做了详细分析,发现一个惊人的事实:
- Action(模型产生执行工具的指令)仅占约 6.5%
- Reasoning(模型自己的思考与输出)仅占约 9.6%
- Observation(来自外界的输入,如文件内容、工具返回的日志等)却占据了高达 84%
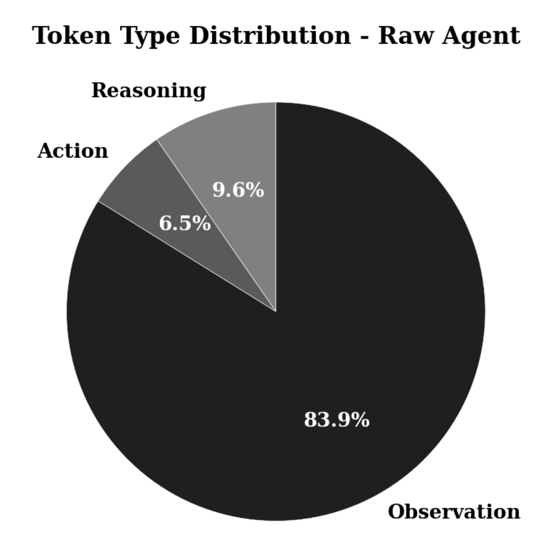
Token 来源分布(数据来源:When Less is More: On the Cost-Effectiveness of Observation Masking in LLM Agents)
另一篇聚焦软件工程场景的论文也得出几乎一致的结论:Agent 仅有约 12% 的 context 花在执行代码、11.8% 花在修改代码,而高达 76% 的 context 用于将整个代码仓库读入。这意味着,真正吞噬上下文窗口的罪魁祸首,不是模型自己的思考,而是那些未经筛选的外界输入。
既然如此,最有效的策略不是等它们把 context 撑爆后再压缩,而是在进入语言模型之前,就先做过滤。
📖 智能读取
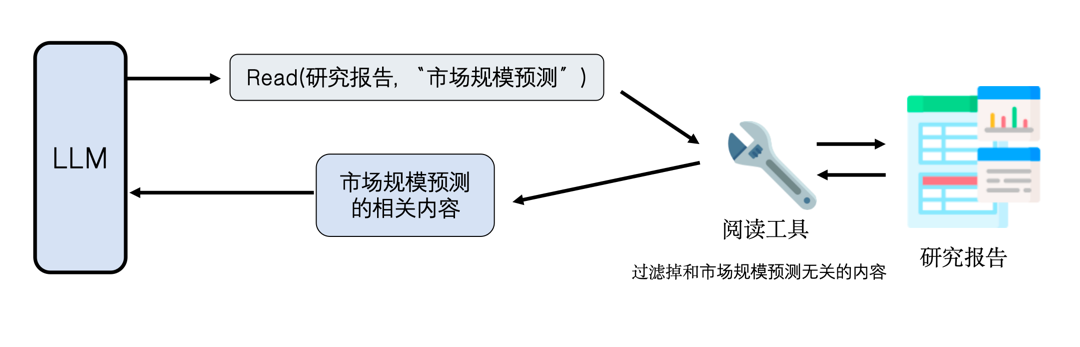
传统的读取逻辑往往是:模型说“我要读一份行业研究报告”,read 工具就把整份上百页的报告原封不动地塞给模型。资料一庞大,模型很容易被“哽到”。
更聪明的做法是,让模型在发出读取指令时就带上筛选意图,例如:“我要读这份报告中关于市场规模预测的部分”。而 read 工具本身也不应只是“打开文件”,它还需要具备一定的智能,能够根据指令从海量内容中找出真正相关的段落。这背后的实现可以是一个小型语言模型——它接收读取指令,从原始资料中筛选出匹配内容,再传给主 Agent。主 Agent 因此只需聚焦于经过过滤的精华信息。
这种“只取一段”的思路,与 小龙虾🦞(OpenClaw) 中 记忆读取 的设计异曲同工。OpenClaw 没有一次性读取整个记忆文件,而是先通过记忆检索找到目标位置,再指定“从第几行开始读、读多少行”,只取出所需的那一小段。本质上,这也是一种预过滤。
📦 按需加载
智能预过滤的另一个典型场景,是工具的按需加载。
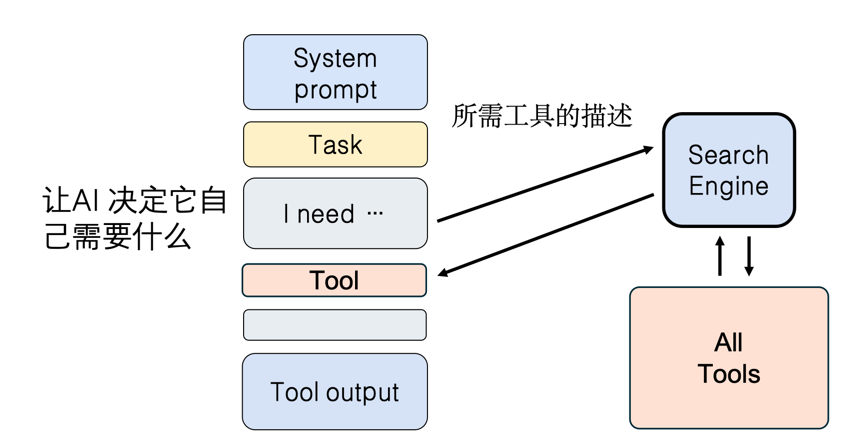
当 Agent 集成了大量工具时,如果每次调用都把全部工具的详细描述塞入 system prompt,上下文很容易被不必要的工具定义撑爆。更合理的做法是:让 AI 自主判断当前任务需要哪些工具,只将真正相关的工具描述动态挂载到上下文中,无关工具则保持在外部、不占用宝贵的上下文空间。
实际上,这种“按需加载”的思路并不仅限于工具。我在《别再复制粘贴提示词了!AI Agent Skill 到底是什么?》一文中提到的 Agent Skill 机制,也正是采用了同样的策略——把各种格式化Prompt模板写成独立的 Skill 文件,仅在检测到用户需要某项 Skill 时,才将其对应的模板动态注入上下文,而非全部常驻在 system prompt 里。
关于按需加载与工具动态选择,可参考论文:
MCP-Zero: Active Tool Discovery for Autonomous LLM Agents
https://arxiv.org/abs/2506.01056
⚙️ 自动化上下文工程
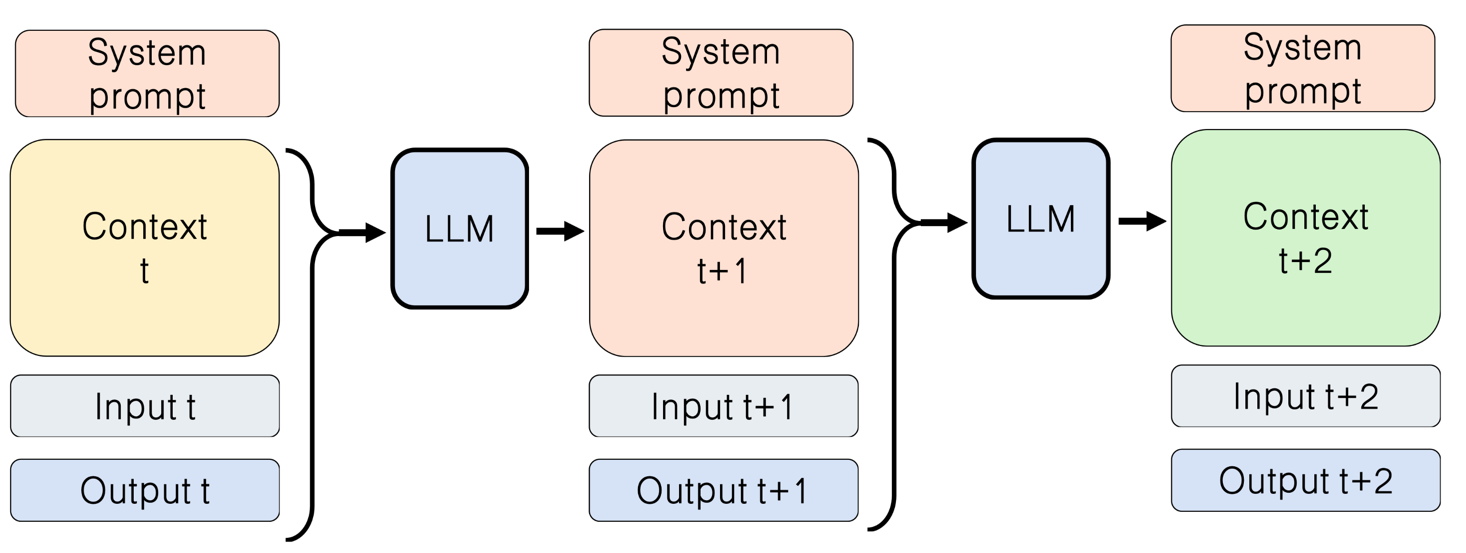
回顾前面的内容,我们讲了压缩与替换、多层级记忆、子智能体、按需加载……这些处理函数 $F$ 的实现方式,本质上都是开发者预先设计好的规则。人类提前把规则写死,程序再按部就班地处理上下文。
但如果我们追问一句:那有没有办法让 Context Engineering 变得更智能呢?
这也是目前很多科技公司和研究机构正在探索的方向——Agentic Context Engineering(自动化上下文工程)。它的核心思路是:与其由人类把所有规则写死,不如尝试将上下文的管理权部分或全部交由 LLM 自己控制。
还记得前面的核心公式吗?
\[C_{t+1} \leftarrow F(C_t, I_t, O_t)\]在 自动上下文工程 的范式下,这个 $F$ 不再是一组人类提前写死的规则,而是由 AI 自己动态决定的——模型根据当前任务自主判断:这一轮上下文该怎么处理,该保留什么、该丢弃什么、该加载什么。
那么,具体是怎么做的呢?下面介绍一种基础实现思路:
具体来说,每一轮模型都会把当前的上下文、用户输入和模型输出放在一起,总结提炼出一份新的上下文。下一轮,这份新上下文再和新的用户输入与模型输出一起被再次总结。如此循环往复,上下文就在一轮轮的自我提炼中不断更新。当然,由于整个过程高度依赖大语言模型的自主判断,它也同样需要面对模型不确定性所带来的潜在风险。
关于自动化上下文工程的详细研究,可参考论文:
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Model
https://arxiv.org/abs/2510.04618
💬 结语
回顾全文,我们介绍了多种 Context Engineering 的手段:压缩替换、多层级记忆、子智能体隔离、按需加载,以及让 AI 自主决策的自动化上下文工程。它们本质上解决的是同一个问题——如何在有限的上下文窗口里,让 LLM 看到最有价值的信息。这些方法并非必然的升级替代关系,而是可以根据实际场景自由选择和组合的策略工具。自动化上下文工程的特殊之处在于,它尝试把“该保留什么、该丢弃什么”的判断权交给模型自身,但这并不意味着它一定优于其他方法,更不意味着前面几种手段就过时了。
这背后的核心逻辑始终没有变:Context Engineering 的本质是对输入信息的精细化管理。它的目标从来不是把 Context 塞得越满越好,也不是压得越少越好,而是在“该知道的都知道”和“不该看的绝不干扰”之间找到一个动态平衡点。
值得一提的是,随着长上下文模型的不断发展,有人可能会觉得“窗口越来越大了,Context Engineering 是不是就没那么重要了?”恰恰相反。窗口变大意味着你能塞进去的东西更多了,但同时也意味着噪声和冗余更容易淹没真正关键的信息。如何在更长的窗口里保持精准,将是未来 Agent 系统能否从“能用”走向“好用”的关键分水岭。
归根结底,一个优秀的 AI Agent,比拼的不是集成多少工具、调用多少 API,而是能否在每一次与 LLM 对话时,都让它看到“对的信息”。这,就是 Context Engineering 的价值所在。