💡 AI Agent 核心技术:一文读懂 Harness Engineering
很多时候,智能体做不好,不是因为模型不够聪明,而是因为外部的规则、工具和流程没有搭好。本文用通俗的方式讲清什么是 Harness Engineering,以及它为什么往往比“换更强模型”更值得先做。

🔍 微信扫码或搜索「AI在学」关注公众号
很多人做智能体时,一旦效果不好,第一反应往往是:“是不是模型还不够强?”
但真实情况常常不是这样。
很多时候,你看到的不是它“不够聪明”,而是它“不够稳”。
比如你让它帮你整理一份资料,它可能开头说得头头是道,中途却突然偏题;你让它按步骤办事,它可能跳过关键一步;你以为它已经做完了,回头一看,最重要的检查根本没做。
这类问题当然有一部分和模型能力有关,但还有很大一部分,问题根本不在模型本身,而在模型外面的那套安排。
所谓 Harness Engineering,本质上就是人类为了让模型稳定做事而提前搭好的外部工作框架。
这里的 harness,原本就有“把东西套住、接好、控制住”的意思。放在这里,你可以把它理解成一套把模型“接进工作系统里”的安排。
它不是替模型思考,也不是直接替模型给答案,而是提前把规则、边界和流程安排好,让模型不容易跑偏。
如果把大语言模型比作一个很聪明、但也很容易跑偏的实习生,那么 Harness Engineering 提供的就不是“答案”,而是它的工作手册、工具权限、检查清单和审批流程。
这也是为什么,很多时候同一个模型,放进不同的系统里,表现会像换了一个人。
如果用最简单的话来区分这几个容易混在一起的概念,那么可以这样理解:
- 提示词工程,研究的是“怎么把指令下清楚”。
- 上下文工程,研究的是“这一轮该给模型看什么”。
- Harness Engineering,研究的是“怎么让模型稳定把事情做完”。
💡 先记一句话:
提示词工程管“怎么说”,上下文工程管“给它看什么”,Harness Engineering 管“怎么让它稳稳把事做完”。

一、🤔 为什么单靠“好提示词”还不够
很多人对大模型的理解,还停留在“把提示词写好一点”。
这在单轮问答里通常没问题,但只要任务变复杂,光靠一段提示词就开始吃力了。因为一个真正能干活的智能体,不是只回答一次问题,而是要持续完成一个过程。
换句话说,你需要的已经不是一个“会接话”的模型,而是一个“能把事情一步步做完”的系统。
一旦任务变成“连续动作”,问题就来了:
- 它怎么知道第一步该先收集信息,而不是直接下结论?
- 它怎么知道哪些动作可以做,哪些动作不该做?
- 它怎么知道自己现在做到哪一步了?
- 它怎么判断“真的完成了”,而不是“我感觉差不多了”?
这些问题,已经不是提示词本身能单独解决的了。
再往上一层看,Harness Engineering 处理的,其实就是另一个问题:怎么把模型放进一个可控、可持续、可交付的工作系统里。
⚠️ 真正麻烦的,往往不是模型“不会答”,而是它“不能稳定做完整件事”。
二、🧭 什么是 Harness Engineering
前面先讲了它和另外两个概念的区别,这里再把它的结构拆开看。
它的重点不是模型“想到了什么”,而是人类“提前安排了什么”。
如果再说得更生活化一点,它就像你在带一个能力不错、但经验还不够稳定的新同事。你不会只丢给他一句“你去办吧”,而是会告诉他目标是什么、哪些事情可以自己决定、哪些事情要先确认、做到什么程度才算真的完成。
这套安排通常可以分成三个层面:
- 通过人类语言来控制模型的“认知框架”。
- 通过工具来控制模型的“能力边界”。
- 通过工作流程来控制模型的“行为方式”。
你会发现,这三层分别对应三个常见失控点:
- 理解错了任务,就会一开始就跑偏。
- 能力边界不清,就会乱试、乱改、乱碰。
- 行为过程没有约束,就会跳步、漏步、提前收工。
所以,Harness Engineering 本质上做的事,不是让模型“更聪明”,而是让模型“更稳”。
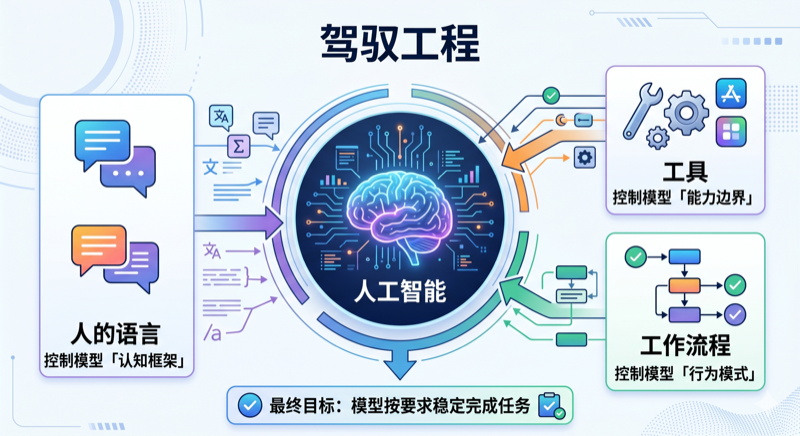
可以把这三层先粗略记成:
语言层管理解,工具层管权限,流程层管执行。
三、🗣️ 第一层:通过语言,先把方向说明白
很多时候,模型不是不会做,而是一开始就理解歪了。
比如,你让它“整理一下这份材料”,你真正想要的可能是“先读完,再提炼重点,最后整理成适合转发的版本”;但如果你没说清楚,它可能会直接开始改写,甚至把重点都改丢了。
这时,最先起作用的不是工具,而是语言规则。
最典型的做法,就是给模型一份长期有效的工作规则。在工程实践里,它常常表现为 AGENTS.md 这类规则文件。
这类文件的作用,不是教模型某一道题怎么做,而是在反复告诉它:
- 先理解任务,再动手。
- 不清楚时先补信息,不要乱猜。
- 哪些地方能动,哪些地方不能动。
- 做完之后先检查,再汇报完成。
再往前一步看,技能说明、工具说明、系统提示,其实也都属于同一类工作。它们共同在回答同一个问题:
模型开始动手之前,脑子里应该先装进哪些规则?
所以,从 Harness Engineering 的角度看,语言不是“包装”,语言本身就是控制。
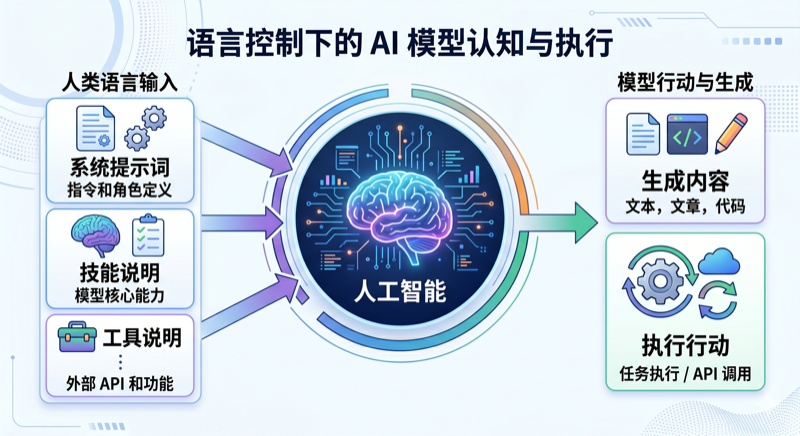
四、🧰 第二层:通过工具,给能力,也给边界
大语言模型本身只会生成文字。它之所以能读文件、改内容、运行命令、调用外部服务,不是因为它自己突然会了,而是因为人类给它接上了工具。
但工具的意义,不只是“增强能力”,更重要的是“划清边界”。
你给它什么工具,它就能把行动延伸到哪里;你不给它什么工具,它就只能停在那个范围内。
这个道理其实不难理解。你让一个实习生帮你处理事情,不会一上来就把所有账号、所有权限、所有文件都交给他。你通常会先给他完成当前任务所需要的那一部分能力。
放到智能体系统里,也是一样的。常见做法包括:
- 给它完成任务需要的工具,而不是把所有能力一次性全开。
- 提前规定哪些内容能看、哪些内容能改。
- 高风险动作单独限制,不让它想做就做。
- 不同角色给不同权限,避免谁都能碰所有东西。
这背后的思路很重要:不是先把能力全给出去,再期待模型自觉克制;而是先把边界画出来,再让模型在边界内发挥。
很多系统之所以不稳定,不是因为工具太少,恰恰是因为工具太多、边界太松、说明太模糊。
五、🔁 第三层:通过流程,把“会回答”变成“会做事”
如果前两层解决的是“怎么理解任务”和“能做到什么”,那么第三层解决的,就是另一个关键问题:
模型能不能把一件事稳定地做完。
真正的智能体任务,最怕的不是某一步不会,而是整个过程失控。比如:
- 做着做着忘了原目标。
- 中途漏掉关键步骤。
- 一次想做太多,结果半路崩掉。
- 没验证就宣布结束。
所以,一个成熟的 Harness Engineering 方案,通常不会让模型“一路自由发挥到底”,而是会给它设计清楚的过程约束。
这一层的核心,不是单纯多加几个步骤,而是把“计划、执行、校验、授权”拆开管理。
常见的几种做法包括:
1. 计划外化
让模型把任务拆成清单,并明确标记“待做”“进行中”“已完成”。
这样做的价值在于,任务状态不再只存在模型脑子里,而是被写到了外部。只要状态被外化,模型就没那么容易在长任务里失去方向。
2. 分阶段推进
不要让模型一上来就“一口气做完”。更稳的做法通常是:
- 先看清任务和现有信息。
- 再补齐需要的材料。
- 列出计划。
- 只执行当前最重要的一步。
- 做完验证,再进入下一步。
这看起来很朴素,但它恰恰是在防止模型最常见的毛病:急着动手、急着结束、急着自我肯定。
3. 子代理委派
当任务很大时,可以把局部问题拆给子代理处理,主代理只拿回结论,不背负所有中间过程。
它的意义不只是并行,更重要的是隔离。复杂过程被关在更小的上下文里,主流程就更不容易被海量细节拖垮。
4. 人工审批
有些动作不能完全自动,比如修改关键文件、执行高风险命令、调用昂贵接口。这时就应该在关键节点插入审批,把控制权收回到人手里。
这不是“不相信模型”,而是承认一个事实:有些责任,本来就应该由人来兜底。
🔁 这一层真正要解决的,是四件事:
有没有计划、会不会按顺序执行、做完有没有检查、关键动作有没有人兜底。
六、💡 为什么很多时候,先做 Harness Engineering 比先换模型更值
换更强的模型当然有用,但它往往解决不了这几类根本问题:
- 不看环境就开始猜。
- 没有边界就到处试。
- 没有状态记录就越做越乱。
- 没有验证闭环就提前收工。
这些问题,本质上都不是“智力不够”,而是“系统安排得不够完整”。
也正因为如此,很多时候你会看到一个现象:
同一个模型,在一个松散的系统里可能表现得不稳定;换到一个规则清楚、工具受控、流程完整的系统里,往往就会稳很多。
所以我越来越觉得,真正决定智能体上限的,未必只是模型有多强,而是人类有没有把它放进一个靠谱的工作框架里。
✅ 换模型解决的是“上限”问题,Harness Engineering 解决的是“稳定交付”问题。
七、📌 最后一句话
如果提示词工程研究的是“怎么把指令下清楚”,上下文工程研究的是“该给模型看什么”,那么 Harness Engineering 研究的就是:
怎么让模型在真实世界里,持续、稳定、可控地把事做完。
很多时候,模型做不好,不是因为它不够聪明,而是因为我们还没有把这套外部安排搭好。
很多人以为智能体做不好,是模型不够强;其实更常见的是,工作系统还没搭好。