💡 AI Agent 核心技术:一文读懂 Agent 以及 Prompt Engineering、Context Engineering、Harness Engineering
Agent 不是一段会调用工具的提示词,而是一套围绕大语言模型搭起来的工作系统。本文从同一个框架出发,讲清 Prompt Engineering、Context Engineering、Harness Engineering 分别在解决什么问题,以及它们是怎样共同决定一个 Agent 能不能把事做完的。

🔍 微信扫码或搜索「AI在学」关注公众号
你会听到有人讲 Prompt Engineering,有人讲 Context Engineering,也有人讲 Harness Engineering。它们看起来都在讨论“怎么把大模型用好”,于是很多人学着学着就容易混乱:
- Agent 到底是不是一段会调用工具的提示词?
- Prompt Engineering 和 Context Engineering 到底差在哪?
- Harness Engineering 听起来像是个更大的新词,它和前两者又是什么关系?
如果不先把这些概念放回同一个系统里看,后面越学越容易碎片化。
这篇文章想先做一件更基础的事:不从零散技巧讲起,而是把 Agent、Prompt Engineering、Context Engineering、Harness Engineering 放到同一个系统里,一次性讲清它们各自负责什么。
先给结论:
如果把大语言模型比作“大脑”,那么 Agent 不是这个大脑本身,而是一套围绕它搭起来的工作系统。
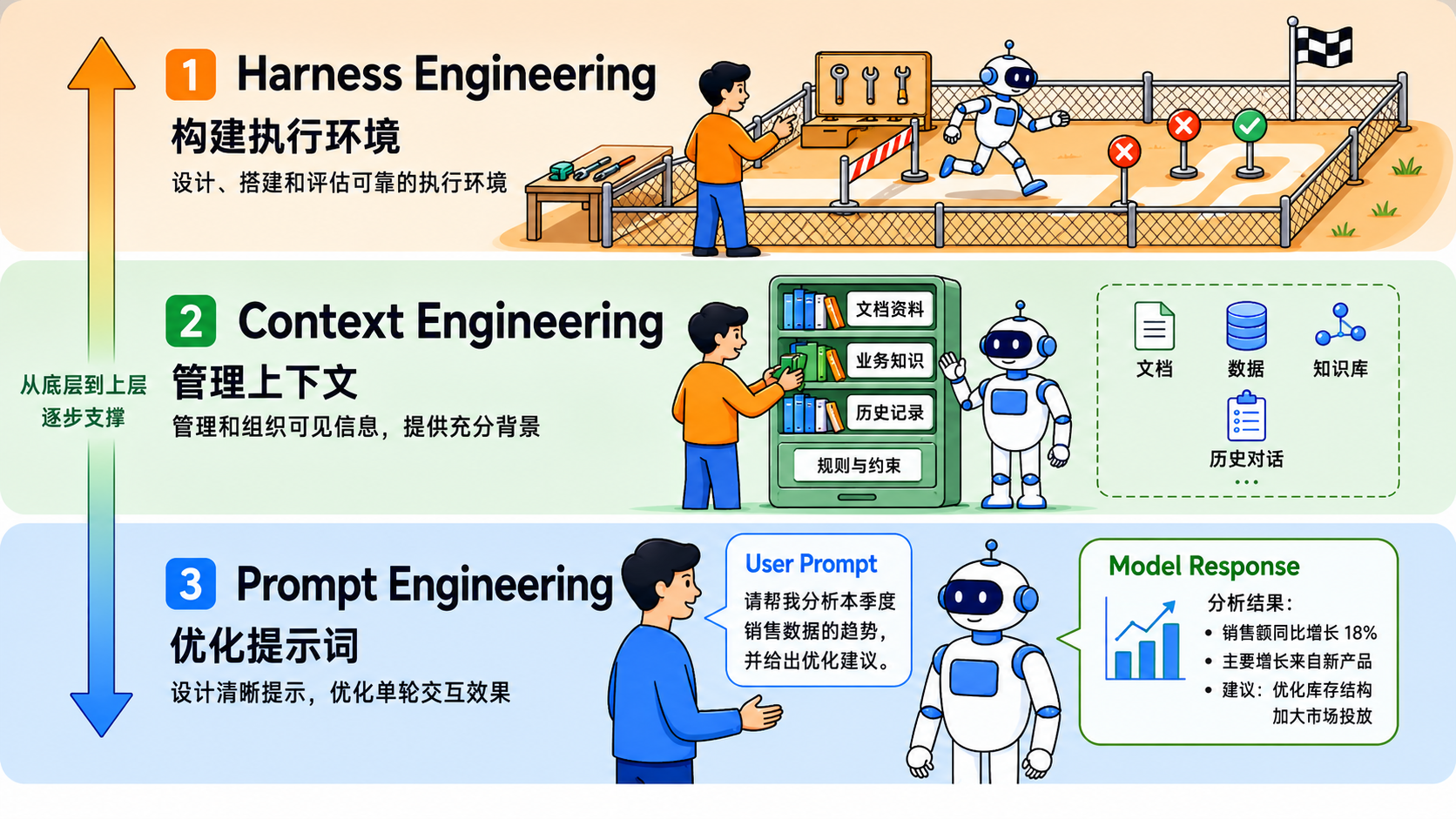
Prompt Engineering,解决“人如何把指令下清楚”。
Context Engineering,解决“这一轮到底该给它看什么”。
Harness Engineering,解决“怎么让它稳定把事情做完”。
一、🤖 先定义:什么是 Agent
很多人第一次接触 Agent 时,容易把它理解成“更高级一点的聊天机器人”。但更准确地说,Agent 是一种能够感知环境、自主规划、进行推理、拥有记忆,并能够调用工具来完成特定任务的智能系统。
不过,先有两个边界要分清:
- 它不是单独的模型本身。
- 它也不是一段一次性提示词。
它强调的不是“一次回答”,而是在一个持续运行的任务回路里不断往前做事。
一个最基本的 Agent,通常包含下面几样东西:
- 一个负责理解、推理和决策的核心能力单元。
- 一套给模型下达任务的规则,也就是提示词。
- 一部分当前要让模型看到的信息,也就是上下文。
- 一组可调用的工具,比如搜索、读文件、改文件、执行命令。
- 一套控制执行过程的外部安排,比如计划、校验、权限和审批。
所以,Agent 更像一个持续运转的工作回路,而不是一次性问答。
它大致可以抽象成这样:
\[\text{观察环境} \rightarrow \text{形成判断} \rightarrow \text{采取行动} \rightarrow \text{获得新反馈} \rightarrow \text{继续下一轮}\]任务一旦进入这种循环,问题就不再只是“模型够不够聪明”,而会立刻变成四个更实际的问题:
- 它有没有真正理解我的要求?
- 它这一轮到底看到了哪些信息?
- 它能调用哪些能力,边界在哪里?
- 它会不会中途跑偏、漏步,或者过早结束?
而这四类问题,恰好对应了后面我们要讲的几个概念。
二、🗣️ Prompt Engineering:解决“人如何把指令下清楚”
所谓 Prompt Engineering,本质上就是围绕“人如何把指令下清楚”所做的一系列设计。
它处理的重点,不是“模型最后怎么说”,而是人如何向模型表达要求。也就是说,它解决的是模型开始行动之前的“理解问题”。
一个相对完整的提示词,通常会包含两组东西:
1. 任务前提
- 角色设定:让模型知道它应以什么身份、什么工作方式来理解任务。
- 背景说明:把任务成立所必需的前提信息先交代清楚。
前者是在定理解框架,后者是在补任务条件。少了这两样,模型往往知道“要做什么”,却不知道“该在什么前提下做”。
2. 执行要求
- 任务描述:明确告诉模型“这次具体要完成什么”。
- 输出结构:提前告诉模型,最后要按什么形式交付。
- 边界约束:哪些事能做,哪些事不能做。
任务越具体,模型越不容易自行脑补;输出要求越清楚,结果就越不容易跑偏。
它的目标很简单:尽可能减少模型对任务的误解空间。
所以,Prompt Engineering 通常会关心这些问题:
- 角色要不要先说清楚。
- 背景是不是交代充分了。
- 任务要不要拆开表达。
- 输出格式要不要提前约束。
- 哪些事能做,哪些事不能做。
像 Chain of Thought、Few-shot 这些常见做法,本质上也都属于这里:它们都是为了减少误解,让输出更稳定。
不过,Prompt Engineering 解决不了全部问题。就算任务说得再清楚,只要模型后面看到的信息不对,或者执行过程没有约束,它一样会跑偏。
三、🧠 Context Engineering:解决“这一轮该给它看什么”
如果说 Prompt Engineering 处理的是“人如何下指令”,那么 Context Engineering 处理的是另一个更容易被低估的问题:
每一轮推理时,到底哪些信息应该被送进模型。
这里最容易踩的坑,就是误以为“给得越多越好”。
如果给得太少,模型会失忆,不知道之前发生了什么;如果给得太多,模型又会被无关信息淹没,推理精度下降,甚至直接超过上下文窗口上限。
所以,Context Engineering 的核心,不是机械地堆信息,而是持续决定“什么该进来,什么不该进来”。
它通常包括这些做法:
- 对历史过程做总结和压缩。
- 把冗长工具结果替换成更短的表示。
- 把信息分成活跃记忆和外部存储。
- 只在需要时读取某一段文件或某一段记忆。
- 通过子智能体隔离海量中间过程。
看到这里,关注点已经不是“任务有没有说清楚”,而是“模型这一轮到底看到了什么材料”。
四、🧰 Harness Engineering:解决“怎么让它稳定把事情做完”
所谓 Harness Engineering,本质上就是人类围绕模型额外搭建的那套外部工作框架,用来控制它怎么执行、能执行到哪里,以及做到什么程度才算完成。
如果说 Prompt Engineering 是在“把指令交代清楚”,Context Engineering 是在“管理供料”,那么 Harness Engineering 处理的就是“如何把模型放进一套可控的执行流程里”。
它通常覆盖三类事情:
1. 通过人类语言来控制模型的“认知框架”
也就是先用语言把模型放进一个明确的理解框架里。
比如:
- 先看清任务,再动手。
- 不清楚时先补充信息,不要乱猜。
- 做完之后先验证,再汇报。
- 高风险动作不能直接执行。
这类要求有时放在系统提示里,有时写在 AGENTS.md 这类规则文件里。它不直接给模型新能力,但会影响模型怎么理解任务、怎么判断轻重缓急。
2. 通过工具来控制模型的“能力边界”
模型能不能读文件、改文件、联网、执行命令,不是模型自己决定的,而是系统是否给它这些能力。
更关键的是,给工具不是重点,给边界才是重点。
你让它能读哪里、改哪里、哪些动作需要确认,这些都属于 Harness 的范围。
3. 通过工作流程来控制模型的“行为方式”
真正复杂的任务,往往不是败在“不会回答”,而是败在“不会稳定推进”。
所以系统通常还需要给它安排:
- 先列计划,再执行。
- 只推进当前最关键的一步。
- 每一步结束后检查结果。
- 关键节点交给人审批。
- 大任务拆给子智能体,主流程只接收结果。
看到这里,你应该能看出一个明显区别:
Prompt Engineering 和 Context Engineering 更多是在影响“这一轮怎么想”,Harness 则是在影响“整件事怎么做”。
五、📌 为什么真正难做的,往往不是 Prompt,而是系统协同
很多人刚开始做 Agent 时,容易把主要精力都放在提示词上。但一旦任务变成长流程,真正决定效果的,往往不再是某一句提示词有没有再润色一下,而是下面这些系统层面的问题:
- 模型有没有拿到正确的信息。
- 冗长信息有没有被提前过滤。
- 工具有没有边界。
- 执行过程中有没有计划和状态。
- 做完之后有没有验证闭环。
很多 Agent 项目的问题,表面看起来像“模型不够强”,但更常见的原因其实是:
- 任务没交代清楚。
- 上下文喂得太乱。
- 外部工作框架没搭好。
换句话说,Prompt Engineering、Context Engineering、Harness Engineering 这三者,不是谁比谁更高级,而是在补同一个系统里的不同短板。
六、✅ 最后收个尾
如果你把大语言模型看成“大脑”,那么:
- Prompt Engineering 是教你怎么把指令下清楚。
- Context Engineering 是教你怎么把材料给对。
- Harness Engineering 是教你怎么把流程管住。
- Agent 则是把这一切真正组装起来、让它开始工作的那套系统。
这也是这篇文章想说明的核心:理解 Agent,不能只盯着 Prompt;真正重要的,是把“语言、信息、工具、流程”放回同一个系统里去看。