大语言模型究竟是怎么工作的?
用最简单的语言,带你了解大语言模型的核心原理:从预训练到强化学习
随着 DeepSeek 的爆火,越来越多的人开始接触和使用大语言模型(LLM)。但很多人也好奇:这些模型到底是怎么”学会”聊天、写作甚至编程的?
今天,我们就用最简单的语言,带你了解大语言模型的核心原理。
什么是”大语言模型”?
简单来说,大语言模型(Large Language Model,简称 LLM) 是用来处理和生成自然语言的人工智能程序。
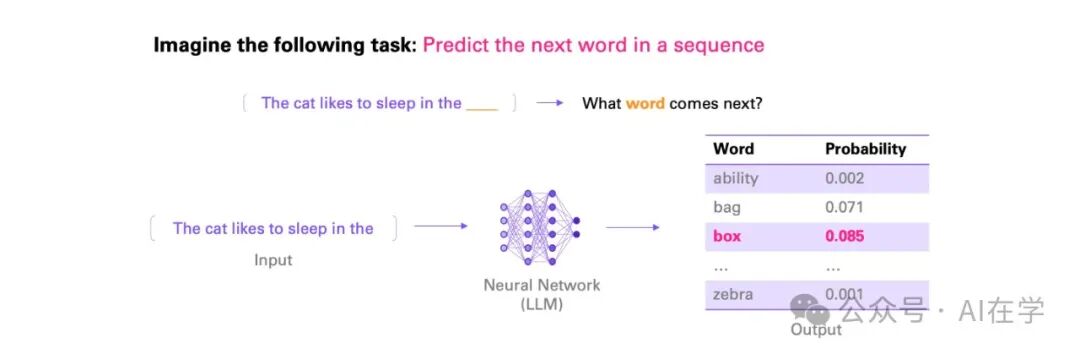
你可以把它想象成一个巨大的”预测引擎“——它的任务就是猜测下一个词会是什么。
比如你输入”今天天气真”,它可能预测你接下来要说的是”好”,然后继续接”适合出门”……
就像玩一个非常高阶的”接龙“游戏。
而它之所以能”猜得准”,是因为它”看过”的文本实在太多了——从百科全书、新闻报道、小说故事,到社交平台的对话,它在训练时读过海量的内容。
它是怎么被”训练”出来的?
训练大语言模型可以分为几个阶段:
🧠 第一步:预训练(Pretraining)
这是模型”打基础“的阶段。它在海量文本上进行”自我监督学习“,通过遮盖部分单词(例如把”我爱吃苹果”变成”我爱吃___“),让模型猜测空白处应该是什么。
这一步并不需要人工标注数据,只依靠原始文本就能学习语言规律。

🛠 第二步:微调(Fine-tuning)
预训练后,模型拥有了语言”常识”,但并不一定符合实际应用需求。比如,它可能会胡言乱语,或者不理解人类指令。
于是,需要在一些带有”人类指导“的数据上进行微调。比如:
- 给模型一个问题,并标注出”最合适”的回答;
- 或者告诉它哪些回答是不妥的。

🏆 第三步:强化学习(Reinforcement Learning from Human Feedback, RLHF)
这个阶段的目标是让模型更”听人话“。
通过人类反馈(比如人类标注员对不同回答进行排序),再利用”强化学习“技术来进一步优化模型行为。
这一阶段确保模型不仅会”说话”,还要”说得得体“。
模型越大就越聪明?
从某种程度上说,是的。
随着参数数量(也就是”神经元的数量”)的增加,模型的表现会显著提升。
你可以想象模型的”大脑”越来越大,它可以记住、理解、表达的东西也就更多。而实际情况也显示,模型一旦达到一定规模,甚至会”涌现“出一些新能力,比如:
- 编程
- 推理
- 语言翻译
等等——这些能力并不是刻意教的,而是在海量训练中”自然“出现的。
不过,模型大,也带来了不少挑战:
- 🖥 训练成本极高(动辄数百万美元的显卡集群)
- 🧮 推理速度慢、资源消耗大
- ❌ 容易”胡说八道”或生成不当内容
模型”真的理解”语言吗?
这个问题颇具哲学性。
模型确实能生成非常像人类的回答,但它并没有”意识”或”理解”——它只是依靠统计规律和大量文本,找到最有可能的”下一个词”。
比如你问”2+2=几”,它也是通过语言模式去猜,而不是像人那样真正计算。
换句话说,它们”会说“,但不一定”懂“。
就像一个”超级会模仿“的鹦鹉,它说得像人,但未必真的”懂”。
那它们有用吗?
尽管不是真正理解,但在实践中,”像懂一样“往往已经足够强大——毕竟,它能帮你:
- ✍️ 写邮件
- 🌐 翻译文档
- ❓ 回答问题
- 💬 陪你聊天
它们擅长把”模糊的问题“转化为”清晰的语言“,而这正是我们日常交流中最需要的能力。
总结:它们不是人类,但也很”聪明”
大语言模型像是一位从未真正经历世界、却读遍人类所有文本的”超级模仿者”。
它不会思考、不会感受,却能说出像人一样的话——这背后的原理既简单又震撼:
通过预测下一个词,就能”模拟”人类语言的复杂性。
所以,下一次你和大语言模型对话时,不妨想一想:
你正在与一个全球最大”预测机器”交流,它虽然没有灵魂,却用数学和数据,在”理解”我们的语言。