一文读懂 RAG 与嵌入模型:大模型如何实现'读文档、答问题'
RAG 本质上是给大语言模型'外挂'了一个知识库,而让这个外挂真正运行起来的,正是嵌入模型
你有没有发现,现在的大语言模型不仅能聊天、写文案,还能读懂你的文档、帮你查资料?
比如:你提问”公司的报销流程是怎样的?”它就能从员工手册中精准找到相关流程;又或者你提问”我们和A公司的合同中,付款条款是怎么写的?”它就能从数十份合同中,精准定位到相关内容,直接告诉你付款方式、周期和违约条款。
这背后的关键技术,就是最近大火的 —— RAG(Retrieval-Augmented Generation,检索增强生成)。
RAG 本质上是给大语言模型”外挂”了一个知识库,而让这个外挂真正运行起来的,正是嵌入模型(Embedding Model)。
它负责将文字转化为向量,构建语义地图,帮助模型”找资料”“看懂上下文”。可以说,没有嵌入模型,RAG 就无法理解问题、无法匹配内容、无法智能生成。
🧭 RAG 是怎么工作的?
简单来说,RAG 就是:
- 📚 先”读资料”:把大量文档通过嵌入模型转成向量,存入一个向量数据库。
- 🔍 再”找资料”:用户每次提问,系统把问题转为向量,在向量数据库中找”最相关的内容片段”。
- 🧾 最后”回答问题”:大模型根据这些上下文,再生成回答。
整个过程的第一步,就依赖嵌入模型。如果嵌入效果不好,RAG 检索的内容就会不相关,输出的回答就会跑偏。❌
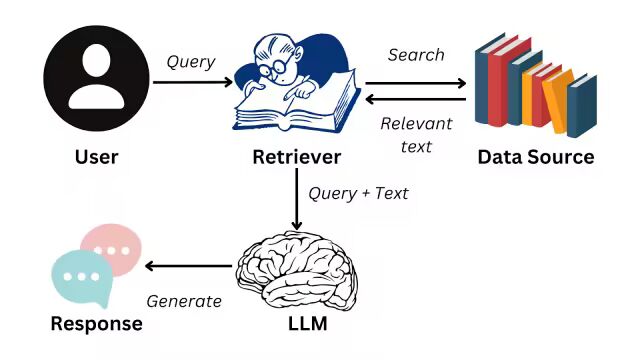
RAG 工作流程:读资料 → 找资料 → 回答问题
🧠 什么是嵌入模型?
嵌入模型的目标是把一段文字,变成一个”向量”——一个多维数字数组。
向量之间的”距离”代表语义上的相似程度。
比如:
- 🎧 “蓝牙耳机” →
[0.01, -0.03, 0.07, ...] - 📶 “无线耳机” →
[0.012, -0.032, 0.068, ...]
它们向量之间的距离很小,说明语义接近。
计算机可以通过这些向量,实现语义搜索、推荐匹配、文本归类等操作。
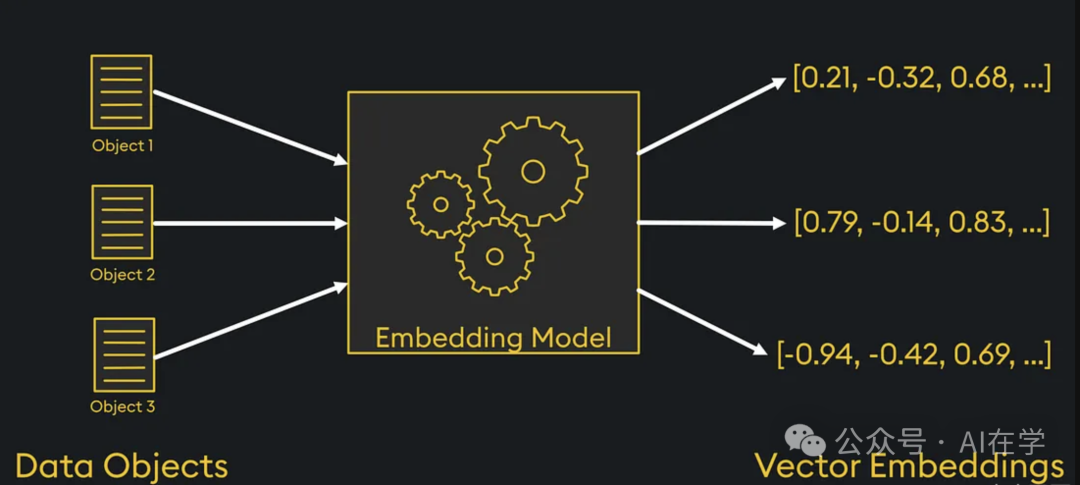
嵌入模型将文字转化为向量,构建语义地图
⚙️ 嵌入模型是怎么工作的?
嵌入过程可以分为几个步骤:
- 📝 输入文字:比如”这款耳机的音质非常棒”。
- ✂️ 分词(Tokenization):拆成一个个词或字(Token)。
- 🔢 初始编码:每个 Token 转为数字表示。
- 🔄 上下文建模:通过神经网络理解词与词的关系。
- 📌 输出向量:返回一个固定长度的向量,比如 768 维或 1536 维。
这个向量,就是这段话的”语义位置”。📍
🔍 嵌入模型在 RAG 中的应用场景
| 应用场景 | 说明 |
|---|---|
| 🔎 语义检索 | 用户问题 → 转为向量 → 在向量库中找”最接近的文档段落” |
| 🧾 文档问答系统 | 给大模型喂”与问题最相关”的语义段落,它就能生成精准回答 |
| 🗣 多轮对话保持上下文一致性 | 通过嵌入来判断用户当前问题和过往内容的关联 |
| 🏢 企业知识库接入大模型 | 用嵌入索引企业文件,帮助员工快速查阅信息或自动写文档 |
💻 代码示例
为了让你更直观地理解嵌入的过程,我们来看一个简单的代码示例:
1
2
3
4
5
6
7
8
9
10
from langchain_openai import OpenAIEmbeddings
# 初始化模型
embeddings_model = OpenAIEmbeddings()
# 输入查询
embedded_query = embeddings_model.embed_query("如何申请开发票?")
# 输出前5维
print(embedded_query[:5])
输出:
1
2
[-0.01569473333775997, 0.012421871088445187, -0.002859314623773098,
0.004997796591818333, -0.007415316816568375]
✨ 这一串数字就是文字的”向量表示”!不同的句子会有不同的向量,而语义相近的句子,其向量也会”靠得更近”。
🧠 小结:嵌入模型,是 RAG 的”视神经”
RAG 的强大之处,不仅是能”调用知识”,而是能”找到最对的知识“。
而这个”找到”的过程,全靠嵌入模型的语义理解能力。📡
未来,无论你是在做企业文档助手、私有化智能客服、还是个人知识管理,嵌入模型都是构建智能系统的第一步。🚀
📚 项目源码
如果你想看看完整代码实现或亲自运行一遍,这里是项目的 GitHub 地址👇:
🔗 https://github.com/zhengjie9510/learn-langchain/tree/main