Token 有了中文名『词元』:AI 时代的度量衡
国家数据局官方定义:Token 中文名为『词元』。探索词元的技术本质与经济学意义,理解 AI 时代的『新能源』

📢 官方定调:3 月下旬,国家数据局在新闻发布会上正式确认——Token 的中文译名为「词元」。这个 AI 领域最核心的术语,终于有了官方认可的「身份证」。
🤔 什么是「词元」?
简单来说,词元(Token)是 AI 大模型处理信息的最小计量单位。
当我们读书看报时,我们看到的是一个个字、一个个词。但 AI 的「大脑」是计算机,它看不懂人类的文字,只能处理数字。因此,我们需要把人类的一句话,切碎成一小块一小块的「基本单元」,然后再喂给 AI。
这个「基本单元」,就是词元。
| 人类视角 | AI 视角(词元拆分) | |———|——————-| | 我爱 AI | [我, 爱, ` AI] | | ChatGPT | [Chat, G, PT] | | 今天天气不错。 | [今天, 天气, 不错, 。`] |
一个 Token 可能是零点几个汉字、一个单词,也可能是一个标点、数字或符号。正如浙江大学柴春雷教授所说:「词」说明它属于语言领域,「元」则是最小、最基础的单位——就像「像素」是图像的最小单元,「词元」就是 AI 处理语言的最小单元。
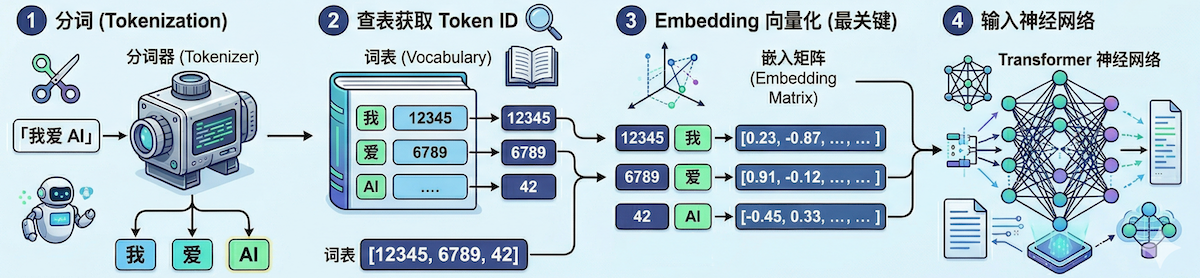
🔄 从文本到数字:词元的完整转换流程
词元只是第一步。真正让 AI “理解”语言的是后续的转换过程。让我们以「我爱 AI」这句话为例,看看它如何一步步变成 AI 能处理的数字:
第一步:分词(Tokenization)
1
「我爱 AI」 → [`我`, `爱`, ` AI`]
第二步:查表获取 Token ID
每个词元在大模型内部都有一个唯一的「身份证号」,称为 Token ID。模型会查询一个预定义的「词表」(Vocabulary):
1
2
3
`我` → 12345
`爱` → 6789
` AI` → 42
于是这句话变成了整数序列:[12345, 6789, 42]
第三步:Embedding 向量化
这是最关键的一步。模型通过一个「嵌入矩阵」(Embedding Matrix),把每个 Token ID 映射成一个高维向量。这个向量不是随便生成的,而是在训练过程中学习得到的,蕴含了词元的语义信息:
1
2
3
12345 (`我`) → [0.23, -0.87, 0.15, 0.66, -0.33, ...] ← 通常有几百到几千维
6789 (`爱`) → [0.91, -0.12, 0.74, -0.05, 0.28, ...]
42 (`AI`) → [-0.45, 0.33, 0.88, 0.21, -0.67, ...]
💡 关键理解:相似的词会有相似的向量。比如「爱」和「喜欢」的向量在空间中会很接近,而「爱」和「桌子」的向量则会相距很远。这就是 AI “理解”语义的基础。
第四步:输入神经网络
这些向量被送入 Transformer 神经网络进行计算,最终生成输出。
🧠 技术本质:从语言到计算几何
著名计算机科学家 Stephen Wolfram 在《What Is ChatGPT Doing … and Why Does It Work?》中深刻地指出:
Token 的出现是人类语言向计算几何转化的关键。Token 不是简单的字符切割,而是将连续的、模糊的人类意义「离散化」为机器可以处理的数字单元。正是因为有了 Token 这一层抽象,AI 才能在概率空间里「行走」,从而在没有显式理解语法规则的情况下,涌现出复杂的逻辑。
换句话说:
- 对人类而言,语言是连续的、感性的、充满歧义的
- 对 AI 而言,语言被拆解成离散的词元,每个词元对应一个向量,在高维空间中进行数学运算
Wolfram 进一步解释,ChatGPT 本质上只是在不断重复一个动作:给定已有文本,预测下一个最可能出现的词元。正是这种看似简单的「接龙游戏」,在数百亿参数和海量数据的加持下,涌现出了令人惊讶的智能表现。
💡 精妙之处:模型并没有显式地存储「意义」「概念」或「理解」,它只是在一个极其高维的空间中,学习到了哪些符号组合是稳定出现的。意义不是语言的前提,而是语言被大规模压缩之后的副产物。
⚡ Token 经济学:AI 时代的「新能源」
英伟达 CEO 黄仁勋在 GTC 2026 大会上提出了一个震撼的观点:
Token 经济学:Token 已经成为衡量智能生产力的唯一标准单位。正如工业时代的「瓦特」或「标煤」,Token 是 AI 时代的能源度量衡。Tokens are the new commodity(Token 是新时代的商品)。数据中心正在演变为「Token 工厂」。
这不是比喻,而是正在发生的现实。
📊 中国词元调用量:爆发式增长
国家数据局披露了一组令人震撼的数据(来源):
| 时间节点 | 日均词元调用量 | 增长情况 |
|---|---|---|
| 2024 年初 | 1000 亿 | 基准 |
| 2025 年底 | 100 万亿 | 增长 100 倍 |
| 2026 年 3 月 | 140 万亿+ | 再增长 40%+ |
140 万亿是什么概念? 相当于全国每人每天平均调用约 10 万个词元(人民日报)。AI 已经深深嵌入了我们的日常生活,只是很多人还没意识到。
🏭 从数据中心到「Token 工厂」
黄仁勋所说的「Token 工厂」正在全球崛起:
- 每生成一个 Token,都对应着真实的推理过程,也对应着真实的电力消耗和算力消耗
- Token 正在成为一种可计量、可定价、可交易的数字商品
- 围绕词元的调用、分发与结算,一套新的价值体系正在加速演进
正如国家数据局所指出:
Token「词元」不仅是智能时代的价值锚点,更是连接技术供给与商业需求的「结算单位」,为商业模式的落地提供了可量化的可能。
🔮 未来:你会收到 Token 账单吗?
想象一下:
- 未来的你,可能会收到一份「词元账单」,代表着你本月动用了多少 AI 大脑来协助工作和生活
- 就像我们现在每个月交水费、电费一样,未来我们或许也要为自己消耗的词元买单
- 企业将以「词元产出效率」作为核心竞争力指标
这听起来像科幻,但实际上,Token 计费已经成为现实。目前市面上大模型 API 的计费方式,已经在按词元计价——输入多少词元、输出多少词元,明码标价。最近养过「龙虾」(OpenClaw)智能体的用户们,对此深有体会——智能体对 Token 的消耗量是普通模型的数倍甚至上百倍。
📝 总结
从 Token 到「词元」,从一个圈内术语到登上国新办发布会,不仅仅是一个新词的出现,更是一个明确的信号:
人工智能正在以前所未有的速度融入中国人的日常。
| 概念 | 含义 | 比喻 |
|---|---|---|
| 词元 | AI 处理语言的最小单元 | 语言的「原子」 |
| 词元经济 | 以词元为核心的价值体系 | AI 时代的「电力」 |
| 词元工厂 | 生产词元的数据中心 | 智能的「发电站」 |
140 万亿只是一个起点。 在这个由「词元」构筑的数字新世界里,我们才刚刚启程。
📚 延伸阅读
- 大语言模型的『翻译秘笈』:一文读懂 Tokens 和 Embeddings
- 大语言模型究竟是怎么工作的?
- Stephen Wolfram: What Is ChatGPT Doing … and Why Does It Work?
参考来源:
- 国家数据局官方发布
- 中国发展高层论坛 2026 年年会
- Stephen Wolfram《What Is ChatGPT Doing … and Why Does It Work?》
- GTC 2026 大会黄仁勋主题演讲